はじめに
こんにちは、カケハシの坂本です。
「AI 在庫管理」というプロダクトの ETL ワークフローに Amazon Aurora のマネージドサービスである Aurora DB Cluster Export という機能を導入したことについてお話しします。
AI 在庫管理では、医薬品などの需要予測を行うために深夜に日次バッチを実行しています。
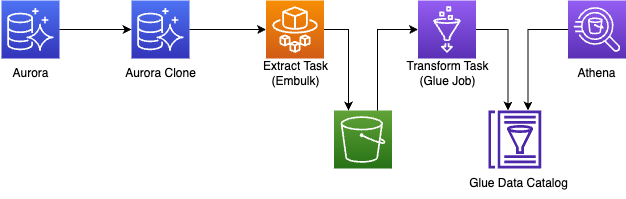
日次バッチでは、バックエンドの Aurora MySQL に格納されているデータの抽出・変換(Extract・Transform)を行い、データマートを作成しています。
全体のオーケストレーションには MWAA (Amazon Managed Workflow for Apache Airflow) を利用しています。
現状の構成
ちなみに Aurora のエクスポート機能にはDB クラスターからデータを取得する方法とスナップショットから取得する方法の二種類がありますが、今回は前者の DB クラスターエクスポートを導入しています。
まとめ
- AI在庫管理では、データ量の増加による RDS からのデータ抽出の実行時間の線形的な増加に課題がありました。
- 今回 Aurora DB Cluster Export を既存の ETL ワークフローに導入することで、データ抽出にかかる時間を 120 分 -> 25 分 に短縮できました。
Aurora DB Cluster Export とは
概要図
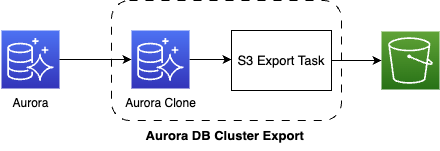
Aurora DB Cluster Export は Amazon Aurora のマネージドサービスであり、Aurora 内のデータを S3 に出力することができるサービスです。
主に以下のような特徴があります。
- DB 内の全テーブルもしくは一部テーブルのデータを S3 に出力することができる。
- 内部的に Aurora Clone が作成され、そのクラスターからデータ抽出が実行される。
- 出力対象のデータは parquet 形式に変換され、
.gz.parquet形式で出力される。
Aurora DB Cluster Export を導入するに至った観点
導入するに至った観点については主に以下のようなものになります。
- パフォーマンス(データ抽出の実行時間)
- こちらがメインの観点となります。
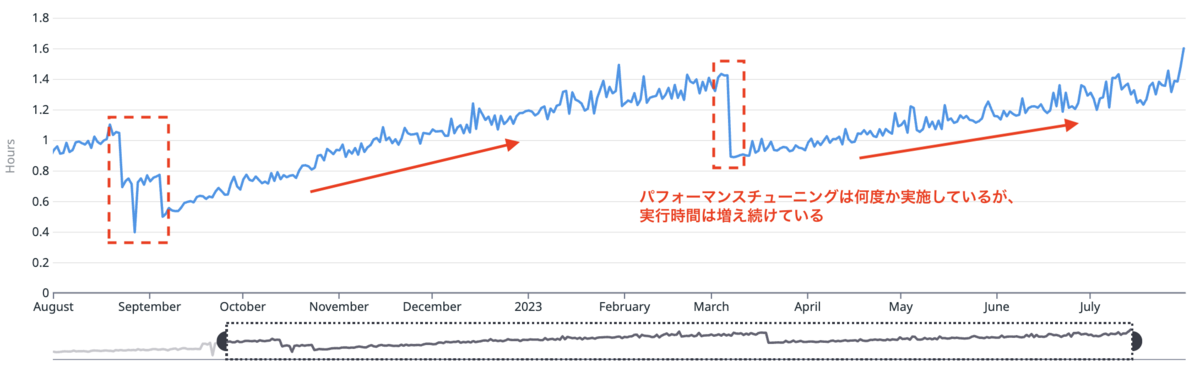
- 旧構成ではデータ量が増えるにつれてデータ抽出の実行時間が線形に増加していました。
- 検証を実施し、Aurora DB Cluster Export ではデータ抽出における実行時間を大きく短縮することが可能であることが分かりました。(実際のパフォーマンスについては後述)
- (Embulk のパフォーマンスチューニングをすることで実行時間を改善できる可能性もあると思うのですが、Embulk の config の調整や AWS Fargate のリソースサイズなど、調整可能な変数が多くチューニングをするにしてもコストを割く必要があると考えました。)
Extract Task の実行時間
- データフォーマット
- parquet 形式で出力されます。
既存の ETL ワークフローでも parquet 形式のデータを出力していたのでマッチすると判断しました。
- parquet 形式で出力されます。
- 保守性
- マネージドサービスなので、コンテナやコードのメンテナンスコストを少なくすることができると期待できます。
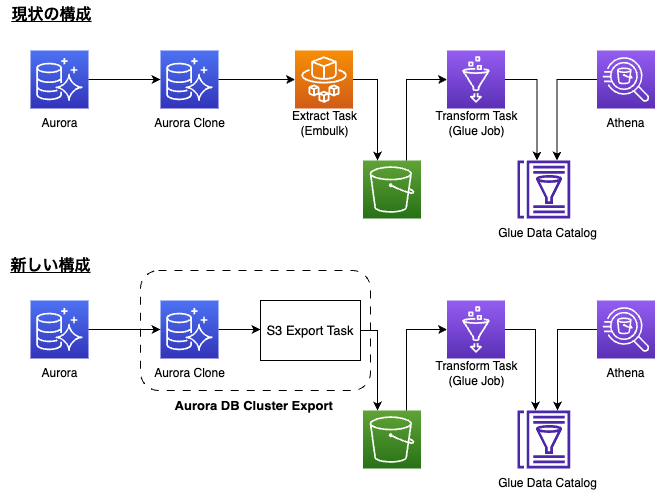
- 既存の構成から移行しやすい
- 旧構成では Aurora MySQL への負荷を抑えることを目的として、ワークフローの中で Aurora MySQL のクローンを作成し、クローン DB からデータ抽出を行っていました。
- Aurora DB Cluster Export の内部でも Aurora MySQL のクローンを作成しており、Aurora MySQL への負荷を抑えることができると考えました。
新旧構成図
パフォーマンス
- 実行時間
- 平均 25 分前後
- Aurora Clone の作成も含めての時間
- 抽出したデータ量を厳密に計測していないのですが、現在 Aurora Export の対象としているのは 合計 380 GB ほどのデータベース内の最もデータ量が多い 5 テーブルとなります。
- Aurora Clone の起動には平均 20 分前後、データの Export は平均 5~8 分前後で完了しています。
- 旧構成における Aurora Clone の起動時間も含めると Extract Task に 120 分前後の時間を費やしていたので、ざっくり 120 分 -> 25 分 まで実行時間を短縮できました!
- 最初は 1 テーブルにのみ適用し、追って4テーブルを追加したのですが、抽出対象テーブル数が増えても実行時間に影響が出ていないことが分かりました。
- 平均 25 分前後
- 可用性
- 失敗回数: 現状 0
- 検証~導入後の期間を含めて約2ヶ月ほど運用していますが、未だ Aurora Export 機能を起因とした失敗はしていません。
考慮すべきポイント/注意点
- Aurora DB Cluster Export は大量の parquet ファイルを出力する場合がある
- 数千万~数億レコードのテーブルを Export すると 1000~3000 ファイル程度の parquet ファイルを出力しました(どのような条件で parquet ファイルを分割しているのかは不明)。
- 後続の変換ジョブでは Glue Job (Spark) を利用しており、大量の parquet ファイルを入力とするとスモールファイル問題を引き起こしてしまう可能性がありそうです。
- ちなみに、数千ファイルではボトルネックになっていなさそうでした。
- データを読み込む側の復号化権限が必要
- Transform Task である Glue Job を実行すると、以下のようなエラーが発生しました。
An error occurred while calling o88.load. The ciphertext refers to a customer master key that does not exist, does not exist in this region, or you are not allowed to access.
- Aurora DB Cluster Export では KMS でデータを暗号化しているため、Glue Job に復号化するための権限が必要でした。(具体的には
"kms:Decrypt"が必要になります)
終わりに
Aurora DB Cluster Export を導入した話について紹介させていただきました。 パフォーマンスについては言わずもがなですが、マネージドサービスということもあって検証/開発/導入まで大きいコストがかからなかったというのも良いポイントでした。 ETL の実行時間周りに困っているけど、大きいコストをかけることができない、、という方へのご参考になれば幸いです。
参考
- https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/export-cluster-data.html
- https://speakerdeck.com/mot_techtalk/aws-aurora-s3-export-woli-yong-sita-fu-he-wokakenai-gcp-bigquery-henodetalian-xi
- https://medium.com/@contactsantoshkumar9/small-file-large-impact-addressing-the-small-file-issue-in-spark-94e1436abe41