こちらの記事はDatabricks Advent Calendar 2023の21日目の記事です。 こんにちは、カケハシのデータ基盤チームでデータエンジニアをしている伊藤と申します。
カケハシのプロダクト1ではRDS(Aurora MySQL/Aurora PostgreSQL)を利用しています。
全社的なデータ活用基盤のプラットフォームとしてDatabricksを採用し、Databricks上でRDSのデータを使用して分析したいという要望が社内で増えています。 そういった要望に応えるためにRDS Snapshot Exportを利用してDatabricksにデータ連携を行ったのでその紹介記事となります。
RDS -> S3にエクスポートする機能
RDSのマネージドサービスでS3にエクスポートする機能は以下の2種類があります。
・DBクラスタースナップショットデータからS3にエクスポート
どちらも既存のDBクラスターのパフォーマンスに影響せず、RDSデータをparquet形式でS3にエクスポートすることができます。
要件としては、既存のDBクラスターのパフォーマンスに影響を与えないことで、 既にスナップショットエクスポートの手法は、Databricks採用前から実現していたため、工数削減から前者を採用しました。
尚、後者のDBクラスターエクスポートは、こちらのブログで紹介しているので興味ある方はご覧ください。
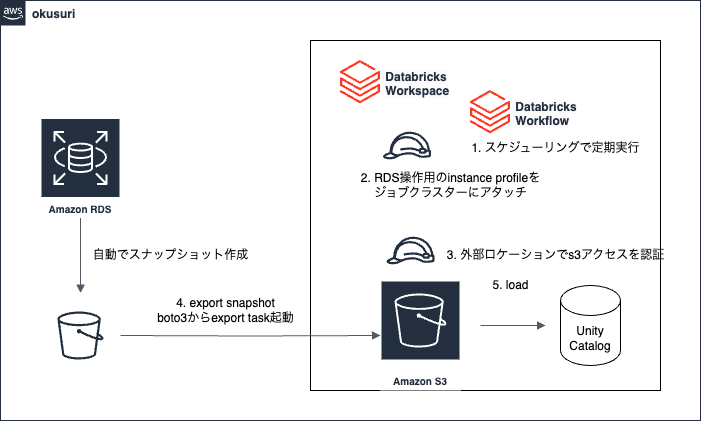
処理の全体像
RDSからスナップショットをとり、S3にエクスポートして、Databricksにデータを取り込む処理の流れは以下になります。
- 全体のオーケストレーションにDatabricks Workflowを使用し、スケジューリングで定期実行
- クラスターにインスタンスプロファイルをアタッチしてRDSを操作
- S3へのアクセスは外部ロケーションを用いて認証
- RDSに対して、snapshot exportを実行
- 出力されたparquetファイルを読み込み、Unity Catalog管理配下にテーブル作成
1. 全体のオーケストレーションにDatabricks Workflowを使用し、スケジューリングで定期実行
以前のテックブログで、dbxを用いてDatabricks Workflowをデプロイする方法についてまとめていますのでこちらをご覧ください。
2. クラスターにインスタンスプロファイルをアタッチしてRDSを操作
IaCの手段としてTerraform Providerが提供されており、弊社ではDatabricks関連のリソースをTerraformでコード管理しています。
Databricksによるチュートリアル記事を参考にクラスターにアタッチするインスタンスプロファイルを作成しました。
# modules/assume_role/ec2/main.tf data "aws_iam_policy_document" "this" { statement { actions = ["sts:AssumeRole"] principals { type = "Service" identifiers = ["ec2.amazonaws.com"] } effect = "Allow" } } resource "aws_iam_role" "this" { name = var.role_name assume_role_policy = data.aws_iam_policy_document.this.json }
# modules/instance_profile/main.tf resource "aws_iam_instance_profile" "this" { name = var.name # ARNから名前を取得 # SEE: https://stackoverflow.com/a/69002757 role = split("/", var.iam_role_arn)[1] } resource "databricks_instance_profile" "this" { instance_profile_arn = aws_iam_instance_profile.this.arn skip_validation = true iam_role_arn = var.iam_role_arn }
# main.tf module "iam_role" { source = "modules/assume_role/ec2" role_name = "instance profile" } data "aws_iam_policy_document" "rds" { statement { effect = "Allow" actions = ["rds:DescribeDBClusterSnapshots"] resources = ["arn:aws:rds:ap-northeast-1:{account_id}:cluster-snapshot:*"] } statement { effect = "Allow" actions = [ "rds:StartExportTask", "rds:DescribeExportTasks" ] resources = ["*"] } } resource "aws_iam_role_policy" "rds" { name = "rds" policy = data.aws_iam_policy_document.rds.json role = module.iam_role.role_id } data "aws_iam_policy_document" "iam" { statement { effect = "Allow" actions = [ "iam:PassRole", ] resources = [ "{rds_cluster_export_role_arn}" ] } } resource "aws_iam_role_policy" "iam" { name = "iam" policy = data.aws_iam_policy_document.iam.json role = module.iam_role.role_id } data "aws_iam_policy_document" "kms" { # SEE: https://docs.aws.amazon.com/AmazonRDS/latest/APIReference/API_StartExportTask.html statement { effect = "Allow" actions = [ "kms:CreateGrant", "kms:Decrypt", "kms:DescribeKey", "kms:Encrypt", "kms:GenerateDataKey", "kms:GenerateDataKeyWithoutPlaintext", "kms:ReEncryptFrom", "kms:ReEncryptTo", "kms:RetireGrant", ] resources = [ "{kms_key_arn}", ] } } resource "aws_iam_role_policy" "kms" { name = "kms" policy = data.aws_iam_policy_document.kms.json role = module.iam_role.role_id } module "instance_profile" { source = "modules/instance_profile" name = module.iam_role.role_name iam_role_arn = module.iam_role.arn }
3. S3へのアクセスは外部ロケーションを用いて認証
DatabricksからS3を参照する際は外部ロケーションを利用しています。 スナップショットが出力されるS3バケットに、ストレージ資格情報と外部ロケーションを作成して認証を行なっています。
4. RDSに対して、snapshot exportを実行
get_export_task_statusは、対象のexport taskがどういう状態なのかを取得する関数になります。 wait_for_export_task_completedは、対象のexport taskを監視する関数になります。
boto3でdescribe_db_cluster_snapshotsのリストから最新のスナップショットを取得し、start_export_taskを実行します。
# Databricks notebook source import botocore import boto3 import time from typing import Literal def get_export_task_status( rds_client, export_task_id: str ) -> Literal["CANCELED", "CANCELING", "COMPLETE", "FAILED", "IN_PROGRESS", "STARTING"]: res = rds_client.describe_export_tasks(ExportTaskIdentifier=export_task_id) if not res["ExportTasks"]: return ValueError(f"RDS export task not found: {export_task_id}") return res["ExportTasks"][0]["Status"] def wait_for_export_task_completed( rds_client, export_task_id: str, sleep_interval: int ) -> None: while True: status = get_export_task_status(rds_client, export_task_id) if status == "COMPLETE": return if status in ("CANCELED", "FAILED"): raise RuntimeError( "RDS export task has finished unexpectedly: " f"export_task_id={export_task_id}, status={status}" ) time.sleep(sleep_interval) DEFAULT_SLEEP_INTERVAL = 60 rds = boto3.client( "rds", region_name="ap-northeast-1", ) # 最新のsnapshotのarnを取得 response = rds.describe_db_cluster_snapshots( DBClusterIdentifier="cluster identifier" ) # cluster_snapshot一覧取得 latest_snapshot = sorted( response["DBClusterSnapshots"], key=lambda x: x["SnapshotCreateTime"], reverse=True )[0] source_arn = latest_snapshot["DBClusterSnapshotArn"] try: rds.start_export_task( ExportTaskIdentifier="ExportTaskの識別子を設定", SourceArn=source_arn, S3BucketName="出力先のS3バケットを指定", IamRoleArn="ExoprtTaskに使用するIAMロールのarnを指定", KmsKeyId="暗号化に使用するKMSを指定", S3Prefix="出力先のS3プレフィックスを指定", ) except botocore.exceptions.ClientError as error: # タスク単体の再実行を考慮し、すでに開始済みの場合はエラーとしない if error.response["Error"]["Code"] != "ExportTaskAlreadyExists": raise wait_for_export_task_completed(rds, "ExportTaskの識別子を設定", DEFAULT_SLEEP_INTERVAL)
start_export_taskを実行することで、以下のS3に対象データがエクスポートされます。
- s3://{出力先のS3バケット}/{出力先のS3プレフィックス}/{ExportTaskの識別子}/<database_name>/
/<parquet-file-name>.gz.parquet
5. 出力されたparquetファイルを読み込み、Unity Catalog管理配下にテーブル作成
4で出力されたs3には対象のDBの全テーブルが出力されているため、dbutils.fs.lsを使用して、対象のs3パスを取得することで全テーブルをブロンズテーブルに書き込んでおります。
build_s3_pathに以下のように1を指定いるのは、RDSからS3へのexport時にparition_indexが切られるためです。
- f"{s3_prefix[0]}/{database_name}/{database_name}.{table_name}/1/"
dbutils.fs.lsで対象のs3_prefixを取得しているのは、ExportTaskの識別子によってs3_prefixが動的に変わるためです。
def build_s3_path(table_name): s3_prefix = [ s3_info.path for s3_info in dbutils.fs.ls(f"s3://{出力先のS3バケット}/{出力先のS3プレフィックス}/) ] s3_path = f"{s3_prefix[0]}/{database_name}/{database_name}.{table_name}/1/" return s3_path for tablename in {連携対象のtable名list}: ( spark.read.parquet(build_s3_path(tablename)) .write.format("delta") .mode("overwrite") .option("overwriteSchema", "true") .saveAsTable("{catalog}.{schema}.{tablename}") )
まとめ
以上、今回はRDSからS3にエクスポートしてDatabricksにバッチ連携する方法を紹介しました。 今回は同一アカウントでのRDS連携を記載していますが、クロスアカウントでの連携も行っています。
また、バッチ連携だけでなく、RDSのデータをニアリアルタイムに取り込みたいという要望は社内で徐々に上がってきています。
直近では、Databricks社がArcionを買収され、DatabricksにIntegrationされることで各データソースから直接Databricksにデータ連携できそうなイメージを持っているため、ゆくゆくはRDSからニアリアルタイムにデータを取り込む記事を執筆できればと思っているのでお楽しみにしていただければと思います。
最後に
データドリブンな組織を目指して、一緒に働いてくださる方はぜひ仲間になっていただきたいと思っております。
- 電子薬歴・服薬指導システム「Musubi」、おくすり連絡帳アプリ「Pocket Musubi」、薬局経営を支援する薬局データプラットフォーム「Musubi Insight」、医薬品発注・管理システム「Musubi AI在庫管理」など。↩