こちらの記事はDatabricks Advent Calendar 2023の16日目の記事になります。
こんにちは。カケハシのデータ基盤チームでデータエンジニアをしている松田です。カケハシでは、2022年7月ごろから全社的なデータ活用基盤のプラットフォームとしてDatabricksを採用し、1年以上経過しました。
今回の記事では、DynamoDBの変更データキャプチャ(CDC)データを利用して、ニアリアルタイムにDatabricksへデータを取り込んだことについての投稿になります。
DynamoDBのCDCデータ利用でリアルタイム化とコスト削減
DynamoDBはカケハシのメインプロダクトであるMusubiで利用しており、そのデータをETL処理して社内でデータ利活用したり、BIツールのMusubi Insightで利用しています。今までは、DynamoDB Exportを利用して全件更新するバッチ処理を行っていました。
しかし、このアプローチではリアルタイム性が不足しており、障害発生時の迅速な調査が難しく、他サービスとのデータ連携時には利用者の要件を満たさないなどの課題が生じていました。また、全件更新であるためインフラコストも大幅にかかっていました。
DynamoDBのCDCデータを利用することにより、リアルタイムなデータストリームが実現でき、これらの課題を解決することができました。
CDCデータをDatabricksへ取り込むアーキテクチャ
CDCデータを利用してDatabricksに取り込む大まかな構成とアーキテクチャは以下になります。
- MusubiのDynamoDBからKinesis Data StreamとFirehoseを利用してCDCデータをS3に連携
- 連携したS3データをDatabricksのAuto Loaderで読み込む
- 読み込んだCDCデータからブロンズテーブルを生成
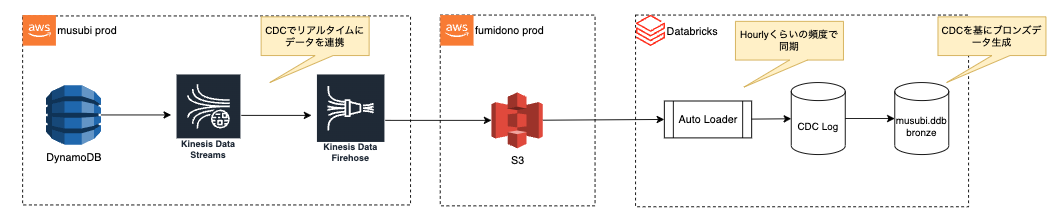
DynamoDBからKinesis Data Stream経由でCDCデータをS3に取り込み
はじめに、DynamoDBが構築されているAWS環境で各テーブルごとに、Kinesis Data StreamとFirehoseをTerraformでリソース追加します。以下、IAM周りのところを除いたTerraformのサンプルコードになります。
# locals.tf locals { kinesis_data_stream_dynamodb_table_list = tolist([ "<対象テーブル名>", ]) }
# main.tf ## Kinesis Data Stream module "kinesis_data_stream" { for_each = toset(local.kinesis_data_stream_dynamodb_table_list) source = "./modules/kinesis_data_stream" dynamodb_table_name = each.key } ## Kinesis Firehose Delivery-stream resource "aws_kinesis_firehose_delivery_stream" "delivery-stream" { for_each = toset(local.kinesis_data_stream_dynamodb_table_list) name = "${each.key}-delivery-stream" destination = "extended_s3" kinesis_source_configuration { kinesis_stream_arn = module.kinesis_data_stream[each.key].kinesis_data_stream_arn role_arn = "<kinesis firehoseのIAMロールARN>" } extended_s3_configuration { role_arn = "<kinesis firehoseのIAMロールARN>" bucket_arn = "<出力先のbucket ARN>" prefix = "${each.key}/" compression_format = "GZIP" processing_configuration { enabled = "true" processors { type = "Lambda" parameters { parameter_name = "LambdaArn" parameter_value = "<kinesis firehoseで利用するLambdaのARN>" } parameters { parameter_name = "BufferSizeInMBs" parameter_value = "1" } # デフォルトの60sだとterraformのdiffが出続けるため、61sを指定(see: https://github.com/hashicorp/terraform-provider-aws/issues/9827) parameters { parameter_name = "BufferIntervalInSeconds" parameter_value = "61" } } } cloudwatch_logging_options { enabled = "true" log_group_name = aws_cloudwatch_log_group.firehose-log-group.name log_stream_name = "S3Delivery" } } } ## Kinesis Data Firehose output logs resource "aws_cloudwatch_log_group" "firehose-log-group" { name = "/aws/kinesisfirehose/sample-dynamodb-firehose" } resource "aws_cloudwatch_log_stream" "firehose-log-stream-s3" { name = "S3Delivery" log_group_name = aws_cloudwatch_log_group.firehose-log-group.name } ## Kinesis Data Firehose Transform Function resource "aws_lambda_function" "kinesis-firehose-ddb-cdc-function" { filename = data.archive_file.kinesis-firehose-transform-ddb-cdc-function-zip.output_path function_name = "kinesis-firehose-ddb-cdc-transformer" role = "<kinesis firehoseで利用するLambdaのARN>" handler = "lambda_function.lambda_handler" source_code_hash = data.archive_file.kinesis-firehose-transform-ddb-cdc-function-zip.output_base64sha256 runtime = "python3.9" memory_size = 128 timeout = 60 } data "archive_file" "kinesis-firehose-transform-ddb-cdc-function-zip" { type = "zip" source_dir = "lambda-functions/firehose-transform-ddb-cdc" output_path = "src/firehose-transform-ddb-cdc.zip" }
# ./modules/kinesis_data_stream.tf ## Kinesis Data Stream resource "aws_dynamodb_kinesis_streaming_destination" "stream-destination" { for_each = stream_arn = aws_kinesis_stream.data-stream.arn table_name = var.dynamodb_table_name } ########## ## Kinesis Data Streams resource "aws_kinesis_stream" "data-stream" { name = "${var.dynamodb_table_name}-data-stream" retention_period = 24 shard_level_metrics = [ "IncomingBytes", "OutgoingBytes", ] encryption_type = "KMS" kms_key_id = "<aliasの設定>" shard_count = 1 stream_mode_details { stream_mode = "PROVISIONED" } }
CDCデータをそのまま連携するとワンラインで出力されるため、後続で処理しやすいようにFirehoseでは改行コードを入れるLambdaを連携しています。
# lambda-functions/firehose-transform-ddb-cdc.py import json import boto3 import base64 def lambda_handler(event, context): output = [] for record in event['records']: payload = base64.b64decode(record['data']).decode('utf-8') row_w_newline = payload + "\n" row_w_newline = base64.b64encode(row_w_newline.encode('utf-8')) output_record = { 'recordId': record['recordId'], 'result': 'Ok', 'data': row_w_newline } output.append(output_record) return {'records': output}
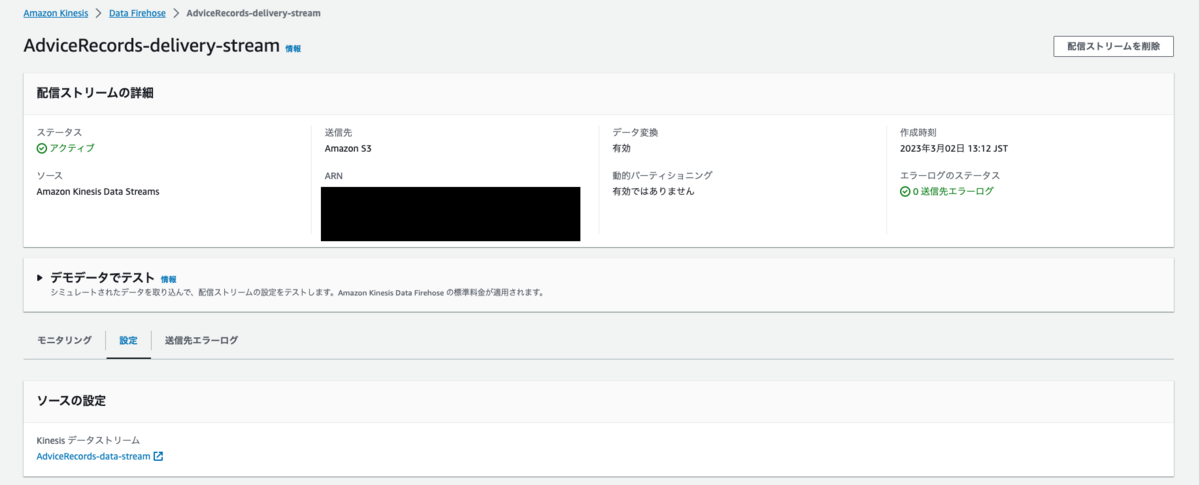
Terraform Applyした結果、以下のようにリソースが作成されます
DynamoDB Streams:
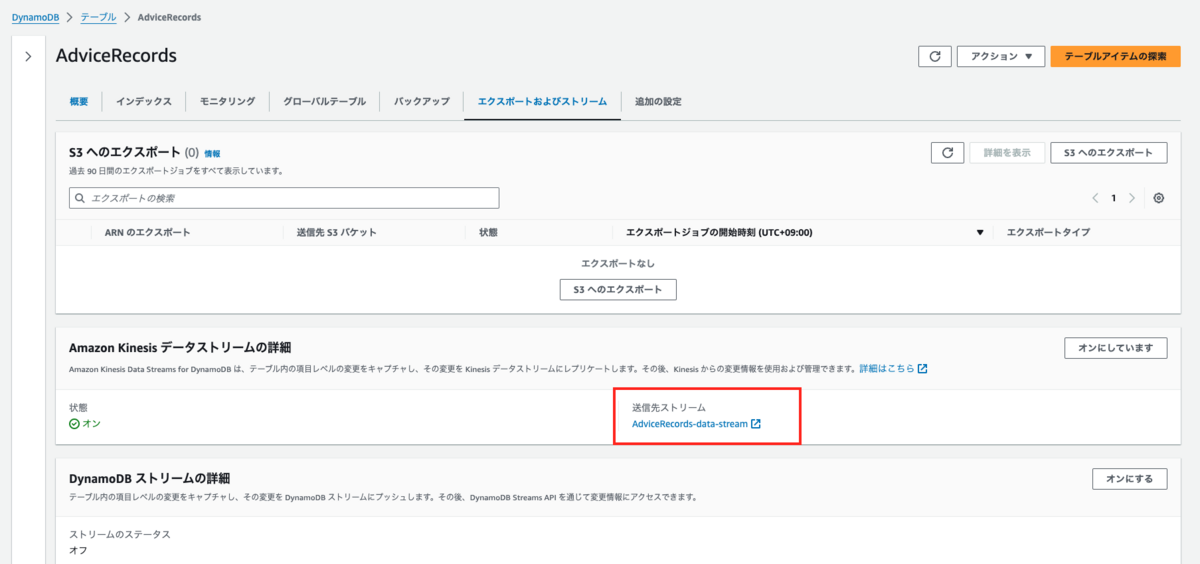
Kinesis Data Stream:

Kinesis Data Firehose:
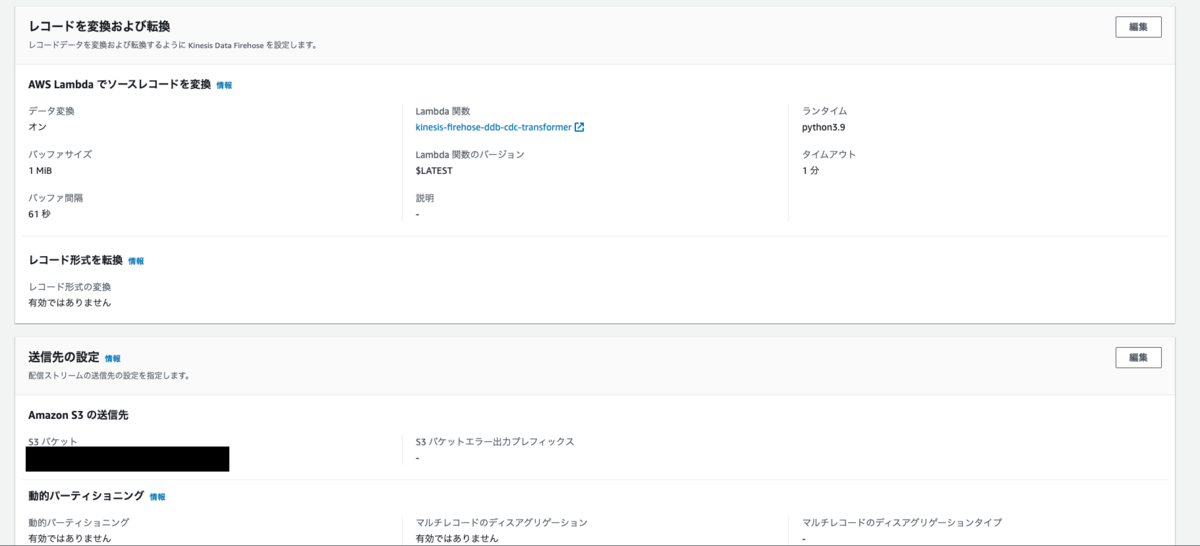
Lambda:
Auto LoaderでDatabricksに読み込み
次に、Auto LoaderでS3からCDCデータをDatabricksに取り込みます。 Auto Loaderはクラウドストレージに到着する新規データファイルをインクリメンタルかつ効率的に処理をします。
取り込みに必要なパラメーターの設定を行います。
# load.py import time from pyspark.sql.functions import lit, expr is_backfill = false # 過去データの取り込みするかどうか input_s3_path = "<入力のS3パス>" checkpoint_s3_path = "<チェックポイントのS3パス>" catalog = "<保存先のcatalog名>" schema = "<保存先のschema名>" table = "<保存先のtable名>" bronze_table_partition_key = "<パーティションキー>" bronze_table_sort_key = "<ソートキー>" bronze_table = f"{catalog}.{schema}.bronze_{table}" bronze_cdc_table_name = f"{catalog}.{schema}.bronze_{table}_cdc" temp_table_name = f"bronze_{table}_tmp" session_time = int(time.time()) # 取り込んだ時間の記録に使用。後続のCDCデータの整合性チェックの時に利用する。
PySparkを使用して、DynamoDBから取得したデータをデシリアイズするためのUDF関数を定義します。DynamoDBの数値型はDecimal型であり、ParquetやDeltaとして出力する際に型エラーが発生する可能性があります。これを回避するために、UDF内でDecimal型をFloat型に変換します。
# load.py def decimal_to_float(record): from decimal import Decimal, Inexact, Rounded from boto3.dynamodb.types import DYNAMODB_CONTEXT DYNAMODB_CONTEXT.traps[Inexact] = 0 DYNAMODB_CONTEXT.traps[Rounded] = 0 if isinstance(record, dict): return {k: decimal_to_float(v) for k, v in record.items()} if isinstance(record, list): return [decimal_to_float(v) for v in record if v is not None] if isinstance(record, Decimal): return float(record) return record def deserialize(jstr): from boto3.dynamodb.types import TypeDeserializer import json if not jstr: return jstr deserializer = TypeDeserializer() jdict = json.loads(jstr) deserialized_jsdict = decimal_to_float( {k: deserializer.deserialize(v) for k, v in jdict.items()} ) return json.dumps(deserialized_jsdict, ensure_ascii=False) deserialize_udf = udf(deserialize, StringType()) def deserialize_single_column(jstr): from boto3.dynamodb.types import TypeDeserializer import json if not jstr: return jstr deserializer = TypeDeserializer() jdict = json.loads(jstr) deserialized_jsdict = decimal_to_float(deserializer.deserialize(jdict)) return json.dumps(deserialized_jsdict, ensure_ascii=False).strip('"')
Auto Loaderを起動するために以下のコードを実行します。 Auto Loaderの設定項目については、以前のテックブログ「DatabricksのAuto Loaderを利用してプロダクトの監査ログを取得した」にまとめていますのでご参考にしてください。
さきほど、設定したパラメーターや作成したUDF関数を利用してS3のCDCデータを読み込み、DatabricksのブロンズCDCテーブルに書き込みをします。
# load.py ( spark.readStream.format("cloudFiles") .option("cloudFiles.format", "json") .option("cloudFiles.schemaLocation", checkpoint_s3_path) .load(input_s3_path) .withColumn("session_time", lit(session_time)) .withColumn( "approximate_creation_datetime", expr("dynamodb:ApproximateCreationDateTime") ) .withColumn("dynamodb_new_image", deserialize_udf(expr("dynamodb:NewImage"))) .withColumn("dynamodb_old_image", deserialize_udf(expr("dynamodb:OldImage"))) .writeStream.format("delta") .option("checkpointLocation", checkpoint_s3_path) .option("mergeSchema", "true") .trigger(once=True) .toTable(bronze_cdc_table_name) .awaitTermination() )
CDCデータからブロンズテーブルを生成
最後に、CDCデータを元にして差分更新でテーブルを作成します。
以下、サンプルコードになります。 Databricksに取り込んだCDCデータからイベントデータを抽出し、セッションとバックフィルの条件に基づいてフィルタリングします。その後、抽出したデータを最新のイベントに集約し、変更結果後のテーブルを一時生成します。
# load.py def build_query_to_agg_cdc(cdc_table_name, primary_key, session_time, is_backfill, sort_key): sql = f""" WITH raw AS ( SELECT eventID, eventName, dynamodb:ApproximateCreationDateTime, CASE WHEN eventName != 'REMOVE' THEN dynamodb:NewImage ELSE null END image, CASE WHEN eventName != 'REMOVE' THEN dynamodb:NewImage:{primary_key} ELSE dynamodb:OldImage:{primary_key} END {primary_key}, CASE WHEN eventName != 'REMOVE' THEN dynamodb:NewImage:{sort_key} ELSE dynamodb:OldImage:{sort_key} END {sort_key} FROM {cdc_table_name} WHERE session_time = {session_time} OR {is_backfill} ), latest_events AS ( SELECT {primary_key}, {sort_key}, MAX_BY(eventName, ApproximateCreationDateTime) eventName, MAX_BY(image, ApproximateCreationDateTime) newImage FROM raw GROUP BY {primary_key}, {sort_key} ) SELECT {primary_key}, {sort_key}, newImage dynamodb_image, eventName latest_event_name FROM latest_events; """ print(f"query_to_agg_cdc_query: {sql}") return sql cdc_agg_sql = build_query_to_agg_cdc( bronze_cdc_table_name, bronze_table_primary_key, session_time, is_backfill, bronze_table_sort_key, ) rdd = spark.sql(cdc_agg_sql).rdd def create_bronze_table_schema(primary_key, sort_key=None): return types.StructType( [ types.StructField(primary_key, types.StringType()), types.StructField(sort_key, types.StringType()), types.StructField("dynamodb_image", types.StringType()), types.StructField("latest_event_name", types.StringType()), ] ) spark.createDataFrame( rdd.map( lambda x: ( deserialize_single_column(x[0]), deserialize_single_column(x[1]), deserialize(x[2]), x[3], ) ), create_bronze_table_schema(bronze_table_primary_key, bronze_table_sort_key), ).createOrReplaceTempView(temp_table_name)
以下のサンプルコードでは、一時生成したテーブルから既存のテーブルが存在すればマージし、存在しなければテーブルを作成します。
# load.py def build_query_to_merge_into_bronze_table( bronze_table, temp_table_name, primary_key, sort_key=None ): sql = f""" MERGE INTO {bronze_table} br USING {temp_table_name} mt ON br.{primary_key} = mt.{primary_key} AND br.{sort_key} = mt.{sort_key} WHEN MATCHED AND mt.latest_event_name = 'MODIFY' THEN UPDATE SET * WHEN MATCHED AND mt.latest_event_name = 'REMOVE' THEN DELETE WHEN MATCHED AND mt.latest_event_name = 'INSERT' THEN UPDATE SET * WHEN NOT MATCHED AND mt.latest_event_name = 'MODIFY' THEN INSERT * WHEN NOT MATCHED AND mt.latest_event_name = 'INSERT' THEN INSERT * """ print(f"query_to_merge_into_bronze_table: {sql}") return sql if spark.catalog.tableExists(bronze_table): spark.sql( build_query_to_merge_into_bronze_table( bronze_table, temp_table_name, bronze_table_primary_key, bronze_table_sort_key, ) ) else: spark.sql( f"CREATE TABLE {bronze_table} AS SELECT * FROM {temp_table_name} WHERE latest_event_name != 'REMOVE'" )
上記の一連の処理をノートブック化して、ワークフローを構築すれば完成となります。 カケハシでそこまでのリアルタイム性が現在は求められていないため、毎時でワークフローを実行しています。
まとめ
今回、DynamoDBのCDCデータを利用して、Databricksにデータを取り組む方法についてご紹介させていただきました。それにより、プロダクト間のリアルタイムのデータ連携が可能になり、コストが大幅に削減されました。
カケハシのデータ基盤チームでは、引き続きDatabricksをフル活用していく想定です。 一緒にDatabricksを使ってデータ基盤構築しませんか。少しでも興味を持ってくださった方がいらっしゃれば以下からご応募お待ちしております。