こんにちは、生成AI研究開発チームのデータサイエンティストとしてAI開発を担当している保坂です。
本記事では、薬局の現場オペレーションを支援するAIを開発する私たちのチームが、ドメインエキスパート(薬剤師など) と データサイエンティスト の協働を円滑にするために構築した「Databricks × Dify x Colaboratory 協働基盤」を紹介します。生成AIプロダクトチームを新たに組成する際におさえたい3つのポイント の記事で、生成AIプロダクト開発にはドメインエキスパート人材の協力が不可欠だということを書いているのですが、その裏側について、深くお話ししたいと思います。
なぜ協働が必要なのか?
薬局業務で使われるような専門性の高いAIは、専門用語・専門知識などの情報をプロンプトに利用する場面が多い為ドメインエキスパートがいなければ全く作ることができません。
例えば何かの情報を要約するタスクをAIに行わせる場合には、漠然と要約の指示をするだけでは適切な出力を得ることは難しいですが、専門知識に基づいて要約の切り口や軸を指定する事で、専門家からみても有用な出力が得られるようになります。また、AIの出力の良し悪しの評価観点や評価軸は専門知識がないと検討できません。
しかしその一方、ドメインエキスパートがいればそれだけでAIが作れるかというと、そういうわけでもありません。AIの品質を多角的に評価して、実用に耐えるものであることを保証するためには、データサイエンティストの持つ専門知識が必要になります。
例えば、ドメインエキスパートが検討した評価観点を具体的な評価指標に落とし込んで定量評価が行えるようにすることは、人手によらない継続的なAIのモニタリングのために重要ですが、これにはAI・機械学習システムの評価方法に関する知識が不可欠です。別の例として、AIの出力の不安定性のコントロールが挙げられます。AIは同じ出力に対して異なる出力を出すことがあるので、一度は適切な出力であることが確認できたとしても、別の実行では望ましくない出力になることもありえます。このようなこともデータサイエンティストがAI/機械学習システムの開発においてよく経験する事柄の1つであり、そのノウハウを活かすことができます。
このように、専門性の高いAIを作り、それをサービスとして提供していくためには、ドメインエキスパートとデータサイエンティストの協働が必要不可欠なのです。
従来のMLと異なるLLM時代の協働の深さ
もちろん、これまでの機械学習(ML)システムにおけるMLOpsやHuman-in-the-loopでも、ドメインエキスパートとの協働はありました。しかし、LLM時代ではその深度がより深まっています。
下図は、従来のMLシステムとLLM時代のMLシステムにおけるHuman-in-the-loopにおけるドメインエキスパートの関わる範囲の違いを示しています。
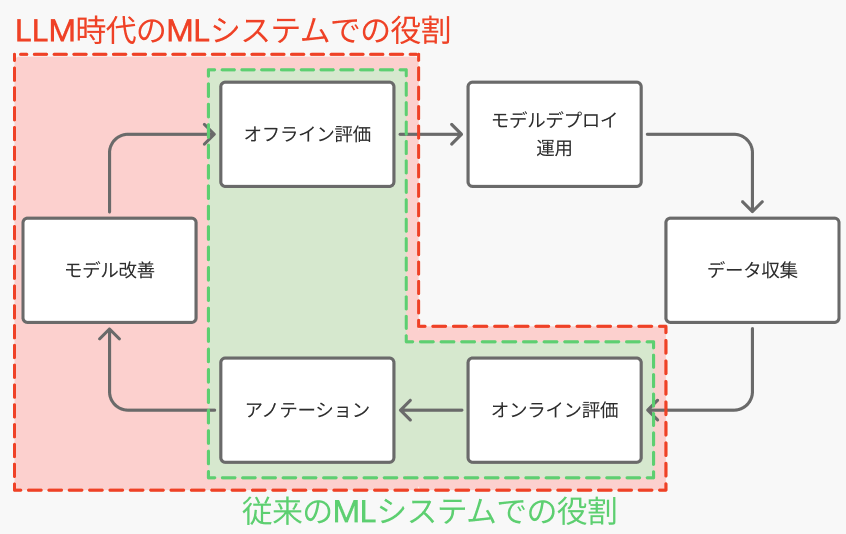
従来のMLでは、ドメインエキスパートの関与は主にデータ作成段階(アノテーション・ラベリング)と最終的な評価段階に限定されていました。ドメインエキスパートが作成したアノテーションや定性フィードバックを受け取り、データサイエンティストが新規データを用いた再学習や特徴量エンジニアリングを通じてモデル改善を行う構造でした。 一方、LLM時代では、プロンプト設計やワークフロー構成といったモデルの詳細にまでドメインエキスパートが直接関与する必要があり、Human-in-the-loopにおける範囲が拡大しています。必要になっている というよりは、モデルの改善のためにモデルの専門知識が必要だった過去と比べて、LLM時代ではプロンプトを修正するだけで改善を行うことができ、その障壁が下がっているので、解きたい課題の知識を豊富に持ち、高速に改善を行う事ができるドメインエキスパートが直接モデル改善を行うことが 必然になってきている 、ということかもしれません。
3つのツールで深い協働を実現する
このような密接な協働を実現するためには、ドメインエキスパートが扱いやすいツールと、データサイエンティストが扱う評価・分析環境をシームレスに連携させる必要がありました。
そこで私たちは、Databricks、 Dify と Colaboratory の3つのツールを連携させて、以下の図のような環境を構築しました。 いくつかの理由で理想と異なる構成になっている点があるのですが、今後理想に近づけていきたいと思っており、最後にそれについても触れたいと思います。 (といっても理由は単純で、急ぎチューニングしなければならないプロンプトやワークフローが多数あったのと、Colaboratoryで動作する過去資産があったので、一時的に環境を理想に近づけることよりもチューニングに時間を割くことを優先したということです)
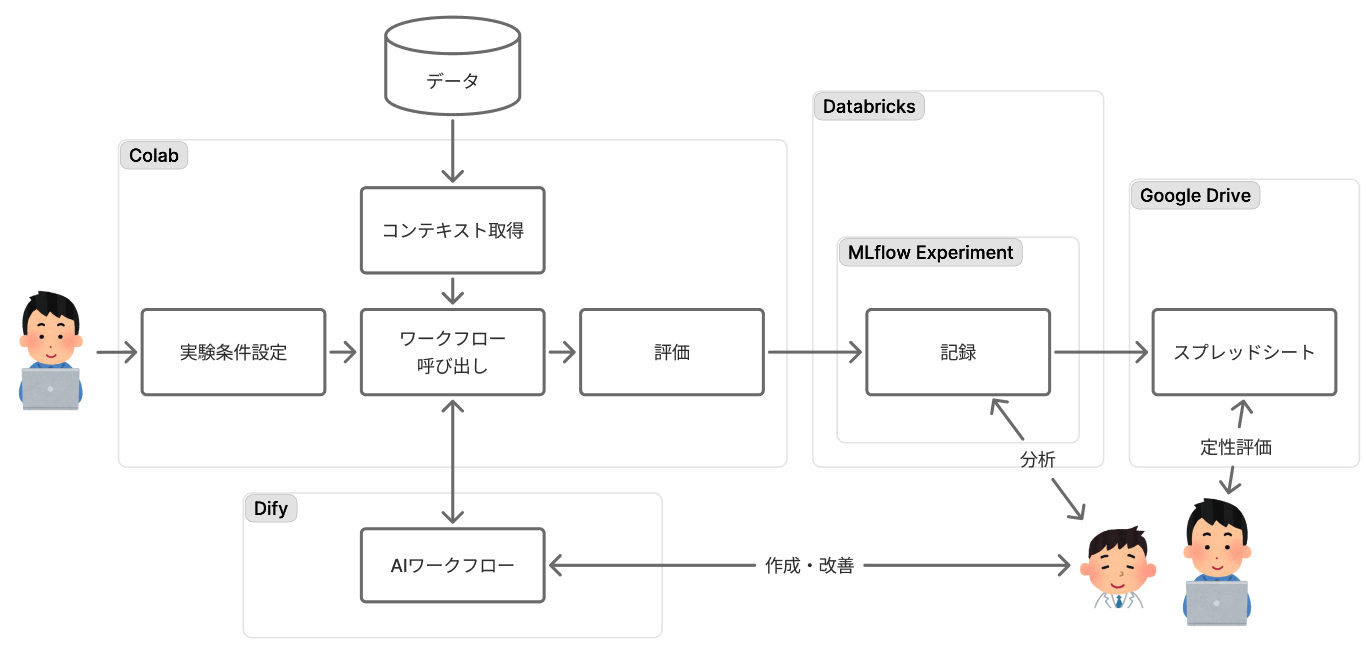
各ツールは以下のような役割を担っています。
- Databricks (MLflow)
実験管理・記録基盤。Colaboratoryでの評価結果(プロンプト、設定, 出力、評価スコアなど)を、MLflow Experimentを使ってすべて記録します。これにより、どんな実験を試したのかが完全に再現可能な形で保存されます。 - Dify
ドメインエキスパートとエンジニアが共同作業するAIワークフロー開発UI。GUIベースでプロンプトを編集したり、複数のLLMを組み合わせたワークフローを直感的に構築できます。 - Colaboratory
データサイエンティストの実験・評価環境。Difyで作成されたワークフローを呼び出し、様々なデータで評価を実行します。
なぜこの構成を選んだのか?
実は、当初は LangSmith と Dify を組み合わせた構成も検討していました。しかし、調査を進めた結果、我々のチームの要件には適さないと判断し、採用を見送りました。主な理由は以下の通りです。
- 連携の制約
評価のためにはDifyで作成したワークフローを実行する必要がありますが、LangSmithからDifyを直接呼び出すことができませんでした。 - 評価機能の制限
我々の専門領域に特化した評価関数を自前で用意する必要があり、既存機能では要件を満たせませんでした。 - 生産性への影響
これらの制約により、LangSmithを導入しても劇的な生産性向上は期待できないとチームで判断しました。
運用してみて良かった点
この環境を実際に運用してみて、特に以下の点は便利だと感じました。
ワークフローの試行錯誤が「高速」になる
ドメインエキスパートがDifyを直接触れるようになったことで、「このプロンプトを少し変えたらどうなる?」というアイデアを即座に試せるようになりました。これにより、改善サイクルが劇的に加速しました。プロンプトだけでなくワークフロー全体の試行錯誤が容易に行える
Dify上では、単一のLLMだけでなく、複数のLLMを連携させるアンサンブルや、不適切な出力を防ぐガードレールといった複雑なワークフローも構築できます。これらの部品を簡単に差し替えられるので、柔軟な試行錯誤が可能になりました。実験記録がいつでも誰でも参照でき、再現できる
MLflowのおかげで、誰が・いつ・どんな意図で試した実験なのかが正確に追跡可能になりました。過去の試行が単なる記録ではなく、チームの共有資産として積み上がっていく感覚があります。
目指すシステム構成
先にも書きましたが、いくつかの理由で現状は理想と異なる構成になっている点があるのですが、もともとは以下の図にあるような構成を構想していました。
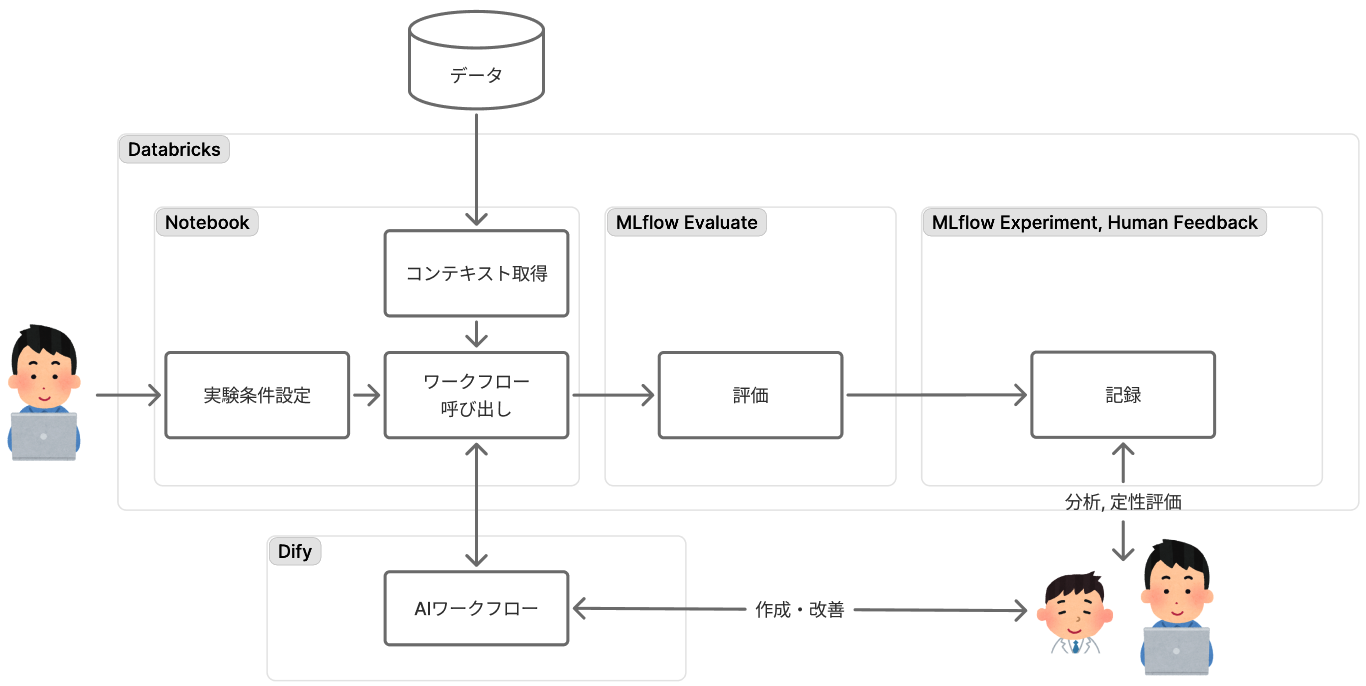
要は「全部Databricks+Difyだけでやっちゃおう」ということです。Databricks Evaluateや Databricks Human Feedback は、プロンプト・ワークフロー改善のために必要な分析、評価(定量、定性ともに)の機能を備えており、それらがシームレスにつながっているので、これを使わない手はないなと言う感じです。近いうちにこのような構成に移行していきたいと考えています。
今後の課題
ドメインエキスパートとデータサイエンティストが協働してAIを構築する環境は整いつつありますが、AIのプロダクト提供や継続的改善においては以下のような課題があり、今まさに解決に向けて取り組んでいるところです。形になってきたらまたブログなどを通じてご紹介したいと思います。
本番環境と実験環境のシームレスな接続
AIの実験環境は試行錯誤が高速になることを重視した構成になっている一方、本番環境ではプロダクトとしての様々な品質要求を満たすべく技術選定が行われているため、利用している技術は異なっています。そのため現在は実験環境で構築したAIワークフローの本番環境への適用には一定の手間がかかります。またAIのリリース前の最終的な品質チェックも難しいところで、大きな手間がかかっています。AIの品質は一般的なシステムのようにダミーデータを用いるだけでは確認しきれず、現実に近いデータを用いる必要があるためです。当然ながら本番環境のデータを品質チェックに用いる事はできませんし、薬局業務支援という専門性の高い領域なので、現実に近いダミーデータを作成する難易度も高いです。このような課題を解決して、実験環境で構築したAIが自動的に品質チェックされ、少ない手間で本番環境に適用できるようにしていきたいと考えています。本番稼働しているAIの継続的モニタリング
本番環境で動いているAIは、実験時には触れてこなかった無数の入力を受けつけることになりますし、先にも述べた通りAIには出力の不安定性があります。そのため実験時には発生しなかったような予期しない出力、問題のある出力がでてくることがないとは言い切れません。このような異常や性能劣化の早期発見と継続的改善のためには、本番稼働しているAIの継続的モニタリングが非常に重要です。今後AIの品質を継続的に監視・評価する仕組みを構築し、より安全で信頼性の高いAIサービスの提供が行える環境を整えていきたいと考えています。
おわりに
今回は、薬局業務支援AIの開発現場で、ドメインエキスパートとデータサイエンティストの深い協働を実現するための環境構築についてご紹介しました。
ツールの得意なことを活かして役割分担をすることで、「高速な試行錯誤」 と 「確かな品質管理」 を両立できる基盤になったと思います。
私たちの取り組みが、同じように専門領域のAI開発で悩んでいる方々の参考になれば幸いです。
最後までお読みいただきありがとうございました!