こちらの記事は カケハシ Advent Calendar 2025 の 2日目の記事になります。
こんにちは!データが好きすぎる梶村(@n_kaji_kaji)です。 カケハシで薬局向けの在庫管理発注システムである「AI在庫管理」というプロダクトのPdMをしていますが、データが好きすぎて担当領域を超えて子会社のデータ移管を行いました。
皆さんの会社にはパッケージの外注基幹システムや開くのに5分かかる巨大なExcelはありますか? 私たちの子会社のファルマーケットには、その両方がありました。
今回は、リソースが限られる中でDatabricksとCursorをフル活用し、ガチガチに固まったレガシーシステムからデータを救い出した話です。
前提:ファルマーケットが抱えていた困難な状況
ファルマーケットでは医薬品の2次流通(薬局間の売買)を行っていますが、データを活用してサービスをより良くしたいと考えていましたが難しい状況でした。
- 完全ブラックボックスな外注システム: DBへの直接接続は不可。データは固定フォーマットのCSV出力のみ。
- データ活用は「巨大Excel」: 出力したCSVを様々な加工をしてからExcelに貼り付け、VLOOKUPとピボットテーブルで戦う運用。
- 計算不能: データ量が膨大になり、Excelが頻繁にクラッシュ。不動在庫(売れ残り)や期限切れ間近の薬がどれだけあるかを誰も即座に把握できない。
「データはあるのに、重すぎて見られない」。そんな中では月次でエクセルから長時間かけて集計した売上などの主要指標を眺めることが限界で、施策の細かな効果測定が難しい環境でした。
戦略:Databricksへのパイプライン構築
カケハシでは全社でDatabricksを活用しています。
そこで、定期的にCSVをDatabricksに取り込み、PySparkで加工して分析可能にする基盤を作ることにしました。
アーキテクチャ構成
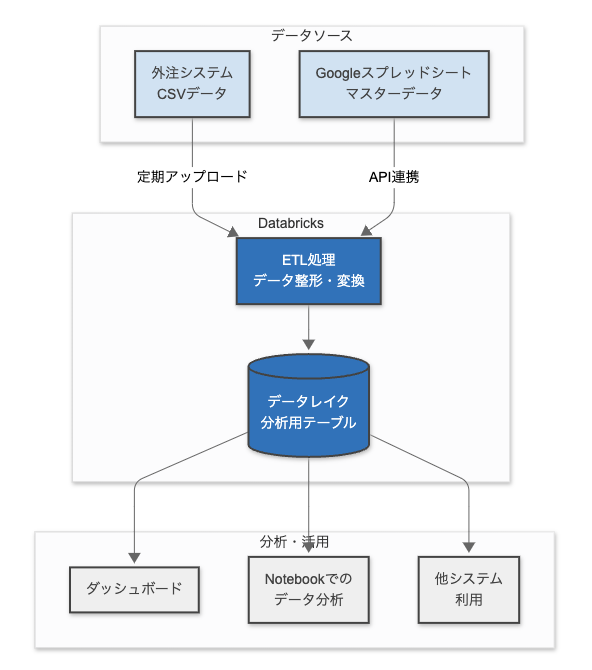
自分はデータエンジニアリングの専門家ではありませんが、この段階では「AIがいれば片手間でもDatabricksへの移管なんてすぐ作れるだろう」と高を括っていました。
壁1:「正規化されていないCSV」と「Excel職人の温かみ」
最初の壁は、データの汚さでした。 普段から在庫管理システムを開発しているので入出庫データの構成はイメージが湧き、AIとER図をさくさく作り、ここまでは順調。しかし、実際にデータを入れると整合性が取れません。
原因を調査すると、衝撃の事実が判明しました。
「CSV出力した後、返品データはExcel上で全く違うフォーマットの一行を手動で追加していた」

また外注システムから出力されるCSVについても正規化されておらず、まだ申し込み段階や検品段階の売買の途中データもカラムが穴だらけで混ざっています。現場では出力したCSVに対して運用書に沿って様々なマクロの実行やソートやフィルターを行った上でExcelにデータを追加しています。エッジケースでは貼り付けたあとにExcel上でデータを直接修正するといった運用をしていたのです。
AIは一般的なデータモデリングが可能ですが、現場の細かな運用や業務ロジックまでは想像できません。結局、普段から業務を理解しExcelを修正している担当者と議論しながら、「確定データの定義とは何か」をロジックに落とし込む作業が必要でした。
壁2:ドメインロジックは「文字列」に宿る
ファルマーケットでは様々な事業を展開しており、様々な経路で医薬品の入庫と出庫が行われます。しかし、パッケージシステムを流用しているため当然明確な「区分フラグ」が存在しません。
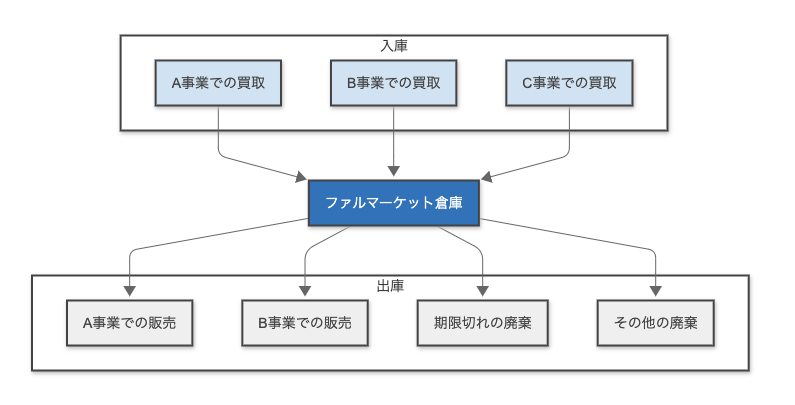
ではどうやって区別しているのか?
- 「入庫元の社名文字列で判断する」
- 「管理番号の接頭辞(Prefix)が '9-' ならA事業とみなす」
- 「B事業の廃棄は廃棄金額には含めない。」
こういった現場の暗黙知が山のようにありました。 これを意識せずに同等のデータとして取り込んでしまえば、データモデルがおかしくなりビジネス的には間違った集計結果を出してしまいます。
結局、「なぜこの数字が合わないのか?」を突き止めるために、開くのも重いExcelを担当者と睨めっこし、エッジケース(例外的な取引パターン)を探し出す泥臭いデバッグに時間を費やしました。
技術的なハマりポイント:DatabricksとCursorのかけ合わせ
AI活用面でも課題がありました。DatabricksのnotebookのAI機能では1ファイルの編集しかできません。ETLの仕組みを作るには重い管理しづらいnotebookになってしまうため、Cursorを使いローカルで業務ロジックなどを別ファイルに切り出しながら構築しました。

実装は基本Cursorが問題なく行えるのですが、以下のような課題がありました。
- 独自の記法: Databricks(Delta Live Tablesなど)独自の記法に対し、AIが古い情報や一般的なSparkの書き方を提案してしまい、そのままでは動かない。notebookからpythonファイルの読み込みエラーが発生する。
- ローカル実行の壁: ローカル環境ではデータの取り込みやテーブル書き込みなどのインフラ層の挙動は再現できず、「書いてはDatabricks上にデプロイしてエラー」のループが発生。Cursor上でエラー解消までを自走できない。
成果:データが見える、意思決定が変わる
泥臭い戦いの末、基盤は完成し、安定稼働できるようになりました。
- 不動在庫の即時可視化: 「半年以上動いていない高額な在庫」がワンクリックで分かるようになりました。
- 攻めの分析: 「どういう薬が不動在庫になりやすいか」を数値で分析可能になり、薬局へのレコメンドメール送信や売買金額の適正化など、攻めの施策が打てるようになりました。DatabricksでのVibe EDAは楽しすぎるのでぜひ! qiita.com
- KPIの透明化: 売上原価や粗利計算はもちろん、今期のターゲット顧客や医薬品に絞った売上なども自動集計され、施策の効果を細かく把握できるようになりました。
学び:データ整備にはドメインへの深い理解が必須
ファルマーケットとはAI在庫管理との連携機能を過去に開発しておりドメイン理解は一定あるつもりでしたが、それでもデータを整理するには現場担当者との連携が必須でした。(片平さん、Excelとの格闘に付き合ってくださり、ありがとうございましたmm)
最近はPalantirモデルが話題ですが、AI活用においてはデータ整備が必須です。そのため、FDE(Forward Deployed Engineer)が常駐し、現場の方と連携してデータ整備を行う重要性が理解できました。(一方で、常駐せずに作った空想のデータモデルでは何も業務を変えられない。)
AIだけでは解決できない泥臭いデータ整備でしたが、リソースの都合でずっとできなかったファルマーケットのデータ移管をAI在庫のPdMをしながら実現できたのはAIのおかげです!時代に感謝!
宣伝
12/4(木)開催のpmconf2025に登壇します! 記事が面白いと思った方はぜひご視聴ください!(後日Youtubeでも配信されるかも?)
おわりに
カケハシでは多様な事業を展開しており、興奮するデータの宝庫です!
少しでも興味が湧きましたらぜひお話ししましょう!