以下資料は先に実施したSREゼミ_信頼性向上編で利用したものです。Well Architected Frameworkの信頼性の柱、その補足資料として読み合わせに使ってください。
Well Architected Frameworkを読み解きながら、信頼性が高まる設計を学びます。 信頼性のほうがメインです。 特に信頼性を高めたい設計者、あとはWell Architected Frameworkを学びたいエンジニアが対象です。
目標: 背景を理解し、基礎技術力を向上させ、設計ポイントが他人に説明できるようになる
コンテンツのありか
ホワイトペーパー(日本語)
どれくらい理解すべきか
一行一行, 一単語一単語に意味があるので全部理解が理想ですが、 まずは要点だけ把握するのを目標とします
REL 1 サービスクォータと制約はどのように管理しますか?
そもそもなぜAWSサービスには細かく多数のサービスクォータが定義されているのか。 ない場合の典型例としてRDBを考えてみる。 DatadogでRDBのメトリクスを見ると、単純なクエリかつCPUなどに大きく余力があったとしても、深夜帯とピーク時間帯でレイテンシが異なっている。分散が大きいということ。 これはnoisy neighbor起因でもあり、リクエスト同時が影響しあっている。RDBはグローバル共有リソースと言える。
一方、DynamoDBの特にgetItemはレイテンシが安定している。 これは制約を明示することで、確実に安定して動作させているから。 利用者の期待(要求)に答えるほか、重いクエリによるカスケード障害を防ぐことができる。非機能要件として不特定多数の顧客に提示することも可能。
制約は力!
逆に(Lambdaと比較した)コンテナ自作Webアプリなどで制約がないとする。 一見自由だが、実際はCPUやメモリ、その他プール類により(暗黙の)制約がある。 制約がどれくらいかはやってみないとわからないし、もし本番で限界まで行ったら全クライアントを巻き込んで大障害になる。不安定な代物
信頼性の側面だけでもクォータの重要性がわかる。 他には使いすぎ予防というコスト面でももちろん大事
more resources
REL01-BP01 サービスクォータと制約を認識する
通信図が書けると良い。 どこからどこにアクセスしていて、どんな制約があるのか
所有するAWSアカウントで設定されているクオータの一覧: https://ap-northeast-1.console.aws.amazon.com/servicequotas/home?region=ap-northeast-1
制約であり、様々な種類がある。回数、ネットワーク、サイズ、ディスク...
そもそも単位を確認すること。アカウント単位、サービス単位など
AWS以外にもある! 社内サービス、外部サービス、Slack...
ドキュメントを読むこと
REL01-BP02 アカウントおよびリージョンをまたいでサービスクォータを管理する
補足なし
REL01-BP03 アーキテクチャを通じて、固定サービスクォータと制約に対応する
soft limitとhard limitがある
soft limit: なんらかの形で上げることができる hard limit: 上げることは不可能。真の限界値
soft limitを設けることでミスや使い過ぎを防止できる。両方確認しましょう
REL01-BP04 クォータをモニタリングおよび管理する
- datadogでも設定すれば確認できます
- soft limitも設定ですぐ対応できるものもあれば、サポート経由など時間かかるものもあります
REL01-BP05 クォータ管理を自動化する
補足なし
REL01-BP06 フェイルオーバーに対応するために、現在のクォータと最大使用量の間に十分なギャップがあることを確認する
障害時にAZ1からAZ2にフェイルオーバーするとします。 同時に動くこともあるので、最大約2倍の容量が必要になります 通常の制約ぎりぎりまで使っていたら即障害です。
早め早めに手を打ちましょう
REL 2. ネットワークトポロジをどのように計画しますか?
基本的に割愛
REL02-BP01 ワークロードのパブリックエンドポイントに高可用性ネットワーク接続を使用する
普通にAWSで作れば問題なし。良い時代
REL02-BP02 クラウド環境とオンプレミス環境のプライベートネットワーク間の冗長接続をプロビジョニングする
オンプレ側があれば優しく保護してあげる必要があります
REL02-BP03 拡張性と可用性を考慮した IP サブネットの割り当てを確実に行う
サーバレスならリスク低
REL02-BP04 多対多メッシュよりもハブアンドスポークトポロジを優先する
割愛
REL02-BP05 接続されているすべてのプライベートアドレス空間において、重複しないプライベート IP アドレス範囲を指定する
割愛
REL 3. どのようにワークロードサービスアーキテクチャを設計すればよいですか?
設計力を高める上でこの項目が重要です。 ここテストに出ます
REL03-BP01 ワークロードをセグメント化する方法を選択する
違うチームが同じリソース(コード、DBなど)を操作しないよう分離しましょう。 信頼性の観点でも、変更の依存関係やワークロード共有による障害のもととなります。
このとき、どうやって分離していくか。 全書き換えによるビッグバンリプレイスは避け、 stranglerパターンで徐々に置き換えていくことが推奨です。 並行稼働のリスクはありますが、 障害の可能性が低いこと、 小さく早めにリリースして新システムを検証できるメリットのほうが大きいでしょう。 ビッグバンリプレイスの悲劇を経験したことない人はそのへんの人に聞いてみてください。
AチームとBチームが同時に作業する必要がある場合、結合度が高いです マイクロサービスに分けたのに同時作業が発生するなら、 分け方を見直しましょう
REL03-BP02 特定のビジネスドメインと機能に重点を置いたサービスを構築する
DDDの領域に近いです。 信頼性の面でのポイントとして、 不適切なチームやサービスの切り分けが不要な変更、改修を誘発し、 障害の原因となります。
無駄がある → 本来不要なことをする → 障害発生確率上昇
すべてはつながっています
REL03-BP03 API ごとにサービス契約を提供する
信頼性の面でのポイントとして、 機械的に影響範囲を通知、確認できれば漏れがなくなるということです。 他チームサービス呼び出しを含むAPIレベルの自動テストにも応用できます。 品質UP!
通常のAPIだけではなく、イベントも同じです。
同一プロダクトでもフロントエンドとバックエンドでチームが別れている場合は契約を結びましょう。 Webアプリの場合はフィーチャーベースでチームを切った密結合でも問題ないですが、ネイティブやクライアントアプリはフロントとバックの切り口でもチームを分けたほうが開発が楽です。
null, 文字列長0, キーなし
地味に障害が起きるのが、
- a: null (各言語のnull相当)
- a: "" (文字列、ただし空文字列)
- 無 (何も入ってこない)
といった空に近いものの扱いです。 配列系の集合も同様です。
言語やSDK、ライブラリによって扱いが異なります。 devtoolsなどで実際のデータを確認しつつ、規約に明記しましょう。 テストケースにも追加しましょう。
*会社で統一が望ましい
単位
書いておきましょう。
文字列
APIの型が文字列、半角英数あたりだとだいたい検討不足です
時刻
保存はUTC+0, APIはJSTが無難。何にせよ明記しましょう
バージョニング
calvarかsemvarか。APIのユーザーは誰かで決めるとよいでしょう
REL-04 障害を防ぐために分散システムでの操作を設計する
ここテストに出ます。
みなさんが作るアプリケーションはすべて分散システムです。 分散システムは必ずどこかで障害が起きます。 あらかじめ障害が起きたらどうなるか確認しましょう。 どのパーツが、どんな障害がおきたら、どうなるか。
REL04-BP01 必要な分散システムの種類を特定する
設計やレビューでよくワークロードについて聞かれると思います。 ワークロードによってどのようなアーキテクチャになるか変わるからです。
よくリアルタイムにしてほしいと言われますが、具体的にはいくらでしょうか? µsオーダー?1秒、10秒、1分、10分...オーダーによって設計が全く異なります。 待てれば待てるほど設計が楽でスケールして安価です。
人間の知覚や画面操作を考えると案外遅らせられるものです。 業務プロセスを聞いてみましょう
ユーザーは深く考えずリアルタイムと言ってみるだけなので、 設計者が深掘り、明示、提案する必要があります
すべてに迅速な応答が必要なわけではないはずです。 なるべく非同期にできる部分を探しましょう
REL04-BP02 疎結合の依存関係を実装する
1 つのコンポーネントを変更すると、それに依存する他のコンポーネントも強制的に変更される場合、それらは 緊密に 結合されています。
e.g.
- 1つのチームが変更すると、他のチームも同時に変更する必要がある
- フロントとバックエンドを同時に変更する必要がある
REL04-BP03 継続動作を行う
カスケード障害予防の話です。ハイレベルの話なので割愛
REL04-BP04 すべての応答に冪等性を持たせる
冪等性の重要性は広く知られているので、実装の話を
REL-05 障害を軽減または障害に耐えるために分散システムでの操作を設計する
すべてのパーツは故障するので、故障しても動くよう、最低限どうなるかはわかるようにしておくこと。
REL05-BP01 該当するハードな依存関係をソフトな依存関係に変換するため、グレイスフルデグラデーションを実装する
Slackが落ちるとプロダクトが落ちる、 通知ウィジェットが落ちるとプロダクトが落ちるといったことがないように
failure modeの話
すべてのサービスは障害を起こすわけですが、すべての原因とその対策を書くことは困難です。サービスの内部でCPUが物理的に全部爆発するかもしれませんし、誰かが電源落とすかもしれませんし、念力でサーバを南極にワープさせるかもしれません
一方、サービスの壊れ方には一定かつ有限のパターンがあります。httpなら応答なし、5XX系、タイムアウト、認証不可などなど。これならクライアントが対策できているかは現実的な範囲でチェックできます。 中身ではなく振る舞いに着目するイメージです。 failure mode(障害モード IT系 /故障モード 工学系)がfailureではなくfailure modeとモードを指しているのは個別の障害ではなくパターンのことです。
FMEA(Failure Mode and Effects Analysis)は全てのサービスのすべての障害モードを洗い上げ、その対策をすべて行い、対策を全部評価することです
完全なものを行う必要はありませんが、担当するプロダクト内のよくある障害モードとその対策は即答できるとよいですね。
ソフトウェアでのサンプルを挙げておきます
FMEAにも限界があり、障害の連鎖系は得意ですが例えば複数箇所の障害が同時に起きることにはあまり強くはないです。
いろいろ書きましたが、こう来たらこうするというのを想定しましょう
REL05-BP02 リクエストのスロットル
サービスクォータをどう読み解くか
1分に500回の制限と記載があるとします。 500回の制限が切れるのはいつでしょうか? rate limitは簡単そうですが、実際にはいろいろな考え方があります。 クォータを読み解くにせよ、実装するにせよ意識しましょう
REL05-BP03 再試行呼び出しを制御および制限する
正直ドキュメントどおりです。
リトライのとき、 jitterを設定しないとどうなりますか? exponential backoffを設定しないとどうなりますか? どの部分でどれくらい再試行しますか? といった問いに答えられるようにしましょう
リトライとタイムアウトは信頼性のための必須科目です
再試行はちょっとした障害に対する対策であり、大障害ではうまく設定しないと被害を拡大させます。その面でrate limitとも関連
REL05-BP04 フェイルファストとキューの制限
キューを削除できるようにしましょう。障害時にキューがたまりすぎて、全部解決するまで復旧できないことがあります
障害復旧時には、障害前の分と障害中の分、障害後の正常な分とまとめて来る可能があります。
REL05-BP05 クライアントタイムアウトを設定する
全API、全コンポーネントのタイムアウトを答えられるようにしましょう
タイムアウトとリトライの整合性も確認しましょう。
リトライとタイムアウトは信頼性のための必須科目です
特にRDB、コンテナなど自分でリソースを管理する必要があるコンポーネントではすぐ障害に繋がります
REL05-BP06 可能な限りサービスをステートレスにする
さすがにステートレスではない作りはなくなってきたので割愛
REL05-BP07 緊急レバーを実装する
REL05-BP01 ができている前提で、最低限ボタン一つでメンテページに切り替えられるようにしましょう
1時間: コードレベル ソースコードrevert 10分: インフラレベル: バイナリ切り戻し 1分: 機能フラグオフ 半日+二次災害: ロールフォワード
REL06 ワークロードリソースをモニタリングする
基本的な統計の話です。グラフの形を把握しましょう。 平均値はその1つの手段/見え方にすぎません。 色んな方向から確認すること
社内Datadogガイドより
平均ではなく、99%タイルやMAX値を見て一番重い部分から対処する - ユーザーのペインが大きい - リソースや各種プールを占有し他に影響が出る - カスケード障害の元になりがち - ピークを元にハードウェア性能を準備することが多いので対処すればコスト削減できる - 外れ値が平均を引き上げていることがある
オペレーションの柱でもあり、信頼性の面でも重要である(コストやセキュリティでも重要!)
REL06-BP01 ワークロードのすべてのコンポーネントをモニタリングする (生成)
synthetic monitoringについて補足
APMメトリクスのような内部数値と比較して、 ネットワークなどを含めた外部から見た状況を評価できる。
単純なheartbeatも悪くないが、smoke testとして例えばログインや基本的なユーザータスクを実行すれば、すぐ障害と影響範囲が検知できる。 KPIやモニタリングなどからは除外できるよう何らかのパラメータなどを入れておくのが望ましい
REL06-BP02 メトリクスを定義および計算する (集計)
メトリクスの定義は確認しましょう 特に平均のような集計値は、なにを集計しているのか。 e.g. 全APIの平均レイテンシ はAPIの平均レイテンシを平均したのか、全データから改めて計算したのか。メトリクスをさらに平均するとおかしかったり、そもそも算術平均で良いのか?などなど
ウインドウ(間隔)も大事です。単位も忘れずに。
REL06-BP03 通知を送信する (リアルタイム処理とアラーム)
オペレーションとも重複します。 通知はアラート、チケット、ログを分けましょう。
アラート-> 即対応する チケット -> あとで対応する ログ -> 一応取っておく
アラートチャネルにはアラート以外いれないようにしましょう。オオカミ少年化するのは整理整頓できていないことが原因です
アラートは飛んでくるたびにそのアラートが正しかったかPDCAを回しましょう
REL06-BP04 レスポンスを自動化する (リアルタイム処理とアラーム)
影響範囲調査のスクリプトなんかも一旦自動化してアラートに添付してもよいかも
REL06-BP05 分析
サーバーログインしたら負け。というのは、セキュリティ面以外にも、一般的なコマンドでは過去データが見れず、現在の情報しか見れないのもあります。 メトリクスを溜め込んだモニタリング基盤にクエリを投げましょう
REL06-BP06 定期的にレビューを実施する
見てない → フィードバックサイクルを回せない → 成果でない、成長しない、アジャイルでもなんでもない
REL06-BP07 システムを通じたリクエストのエンドツーエンドのトレースをモニタリングする
Datadogを使ってある画面アクセスがどのAPIアクセス化まで、RUMとAPMを連携して一気通貫で確認できるように
REL07 需要の変化に適応するようにワークロードを設計する
REL07-BP01 リソースの取得またはスケーリング時に自動化を使用する
基本的にはできているので割愛
REL07-BP02 ワークロードの障害を検出したときにリソースを取得する
割愛
REL07-BP03 ワークロードにより多くのリソースが必要であることを検出した時点でリソースを取得する
割愛
REL07-BP04 ワークロードの負荷テストを実施する
CI上でできることが望ましいですが、そのためにはデータストアもサーバレスである必要があります
REL08 変更の実装
オペレーションの話ですが、これも信頼性に影響あります。 オペレーションの柱ができていないと信頼性が下がりますし、 信頼性が下がるとオペレーションの柱に跳ね返ってきます。
オペレーションできてないのに信頼性高いということはありません。 投資しましょう
REL08-BP01 デプロイなどの標準的なアクティビティにランブックを使用する
手順を書いてから実施してください
REL08-BP02 デプロイの一部として機能テストを統合する
CIにIT/E2Eも入れましょう
REL08-BP03 デプロイの一部として回復力テストを統合する
REL05の机上検証は実際にやってみることで証明されます。 オンボーディングに入れるのもありです。 アラートも検証しましょう
REL08-BP04 イミュータブルなインフラストラクチャを使用してデプロイする
カナリアは使いましょう
REL08-BP05 オートメーションを使用して変更をデプロイする
世の中的にもさすがにアプリの手デプロイは消えましたが、インフラはローカルでIaC実行がまだあるご時世のようです。GitHub Actions化しましょう
DBのカラム変更やアップグレードでメンテナンスが入ることがあります メンテナンスが入ると自動化しづらいです。 モダンなサービスはメンテナンスなしでアップグレードされます。次のレベルに挑戦しましょう。
REL09 データのバックアップ方法
今のところ普通に設定すれば最低限レベルのバックアップはされます。 バックアップは各種障害による全ロストだけではなく、データ上書きからの復旧にも利用されます。そういう意味でS3にもバックアップ(相当)があるのが望ましいです。 バージョニングもあり
REL09-BP01 バックアップが必要なすべてのデータを特定し、バックアップする、またはソースからデータを再現する
略
REL09-BP02 バックアップを保護し、暗号化する
個人情報データをバックアップすれば、そのバックアップも個人情報データです。 基本的にバックアップにはアクセスしないので厳しめがよいでしょう
REL09-BP03 データバックアップを自動的に実行する
略
REL09-BP04 データの定期的な復旧を行ってバックアップの完全性とプロセスを確認する
バックアップ系でいちばん大事なのがこれです。 復旧方法わからなかったらなんの意味もありません。
障害関係は全部、検証と再現、トレーニングまでやってゴールです
REL10 障害部分を切り離してワークロードを保護する
REL10-BP01 複数の場所にワークロードをデプロイする
たまにできていないポイントとしてNAT Gatewayが一つしかないことがあります。NAT Gatewayを排除するか、複数AZに置くか
REL10-BP02 マルチロケーションデプロイ用の適切な場所の選択
割愛
REL10-BP03 単一のロケーションに制約されるコンポーネントのリカバリを自動化する
割愛
REL10-BP04 バルクヘッドアーキテクチャを使用して影響範囲を制限する
Slack含め、多くのSaaSが無償版ユーザーからリリースして様子を見ている。
具体的な仕組み例。 完全cell basedは難しいが、顧客種類分けぐらいなら対応できる。アイデアは理解しやすい。ルーティングどうするとか細かいところを検討する
REL 11 コンポーネントの障害に耐えられるようにワークロードを設計する
REL11-BP01 ワークロードのすべてのコンポーネントをモニタリングして障害を検知する
略
REL11-BP02 正常なリソースにフェイルオーバーする
これも実際にやってみてはじめて証明されます
REL11-BP03 すべてのレイヤーの修復を自動化する
マネージドサービスの多くは自動修復されます マネージドを使う理由の一つ
REL11-BP04 復旧中はコントロールプレーンではなくデータプレーンを利用する
やや難しい話
コントロールプレーンも障害になることがあり、確率としてはデータプレーンより可能性が高いです。特に復旧プロセスではコントロールプレーンの操作呼び出しは控えましょう。例えば自作API中でDynamoDB DescribeTable APIに依存していると、障害に弱くなります。AWS APIのうちControl Plane扱いのものはいざというときにリスクがあります。
Route 53の事例
OK: 障害時にRoute 53のヘルスチェック+フェイルオーバー機能を使う。データプレーンだけで完結し、SLAの範囲内。リスク小。(障害が起きる前に設定している)
NG: 障害が発生したら、Route53のDNS設定を書き換えてフェイルオーバー。DNSの書き換えはコントロールプレーンへのアクセスであり、リスク大
復旧プロセスでコントロールプレーンを呼び出してないか精査しましょう
REL11-BP05 静的安定性を使用してバイモーダル動作を防止する
障害時に普段と動作が違う例
障害が発生してから新しいインスタンス等が起動する:起動の仕組み(コントロールプレーン相当)自体がもともと不安定ですし、障害でコントロールプレーンが影響を受けるかもしれませんし、インスタンスも確保できないかもしれません。BP04で例示した、Route 53で障害時にDNSを書き換える話も同じです
データを取得しに行く:全台再起動などで一斉にアクセスすると新しい負荷であり障害です。タイムアウトや期限切れなども。
REL11-BP06 イベントが可用性に影響する場合に通知を送信する
自動ヒーリングの記録をチケットとしてたまに見返しましょう
REL 12 テストの信頼性
検証までしましょう
REL12-BP01 プレイブックを使用して障害を調査する
調査でもある程度手順を固めておきたいところです。 特に、使っているツールがばらばらだったり、習熟度が異なっているともったいないです。緊急時には対応者が現在もっとも信頼しているツールとやり方を使います。 訓練して良いやり方を採用していきましょう。意外と他人のやり方を見たことないですよね?
必ず実行する作業があれば、通知の時点で自動的に調査ログがでていると爆速です
影響範囲調査と原因調査/復旧は別々の人ができるよう、習熟しておくことが望ましいです
REL12-BP02 インシデント後の分析を実行する
REL12-BP03 機能要件をテストする
機能要件も信頼性のスコープです。QA周りも抑えましょう。自動テストに投資しましょう。設計の段階で怪しいケースを3つ出しましょう
雑な図
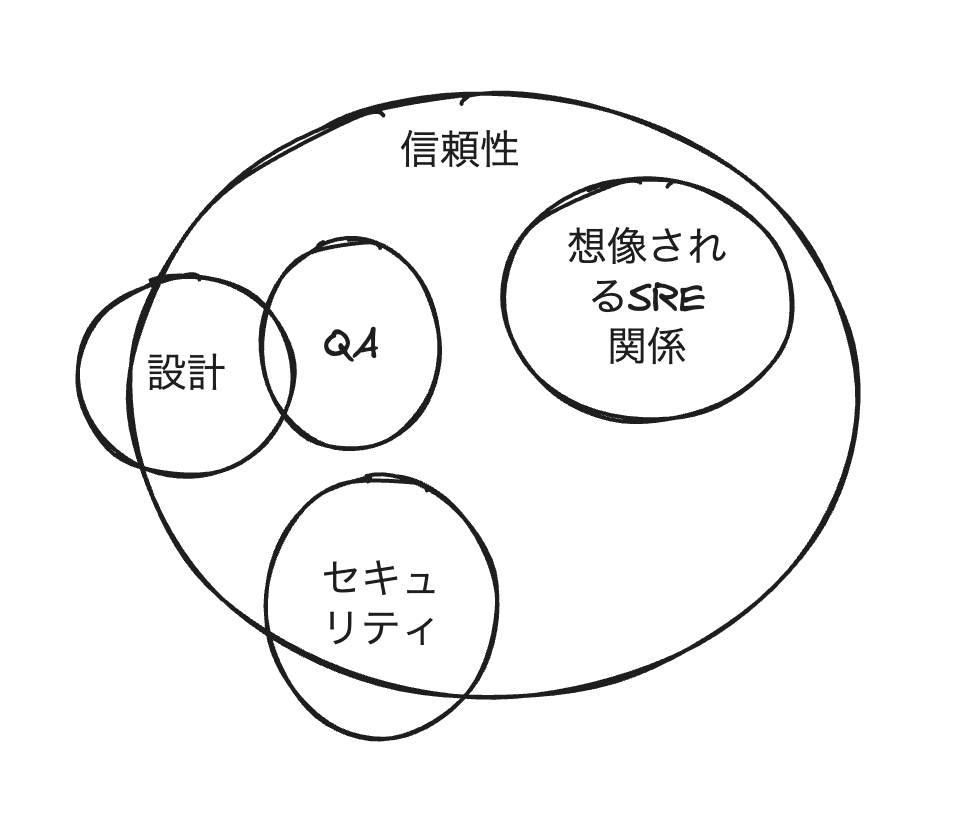
REL12-BP04 スケーリングおよびパフォーマンス要件をテストする
オートスケールするものも、想定通りオートスケールするかどうか検証が必要です。 「想定通り」ということで想定がないのは設計が怪しいです
REL12-BP05 カオスエンジニアリングを使用して回復力をテストする
各コンポーネントに障害が発生したとき、想定通りの動作をしているか。 これも障害(モード)を全部想定しておき、事前に対応策まで考えておく。 その対応策が想定通り動作したか検証するということです。 想定がないのは設計が怪しいです。 もし想定と異なる動作をすれば、学習になりますね。 オンボーディング中に動かすだけでも学習になります。
REL12-BP06 定期的にゲームデーを実施する
REL 13 災害対策 (DR) を計画する
REL13-BP01 ダウンタイムやデータ消失に関する復旧目標を定義する
各ビジネスワークロードごとに優先順位をつけられないかというところが現実的なポイントになります
REL13-BP02 復旧目標を満たすため、定義された復旧戦略を使用する
計画しましょうということです
REL13-BP03 ディザスタリカバリの実装をテストし、実装を検証する
DRも検証が必要です
REL13-BP04 DR サイトまたはリージョンでの設定ドリフトを管理する
DR用の軽量サイトを作ったが、そちらを全然更新していないなど。 CIでまとめて更新が望ましいです 開発やステージング、開発系ツールも準備しましょう
REL13-BP05 復旧を自動化する
自動フェイルオーバーが望ましいですが、テストと、不要なときに動かないことを確認する必要あり
最後に
Well Architected Frameworkを抑えて設計力を磨きましょう
文責: 高木