こちらの記事は カケハシ Advent Calendar 2025 の 4日目の記事になります。
はじめに
生成AI研究開発(GenAI)チームでソフトウェアエンジニアをしている坂尾です。
私たちのチームでは、生成 AI を利用したサービスを開発しています。このサービスでは、Google の Gemini や AWS の Bedrock など、外部 LLM サービスを利用しています。
なお、外部 LLM サービスの利用にあたっては、カケハシでは社内ガイドラインに基づいた厳格なガバナンス体制を設けています。具体的には、CoE(Center of Excellence)組織を中心に、学習データへの業務情報利用の禁止、セキュリティ要件の確認、利用規約の検証など、複数の観点から審査を実施しています。詳しくは、こちらの記事で紹介していますので、ご関心のある方はぜひご覧ください。
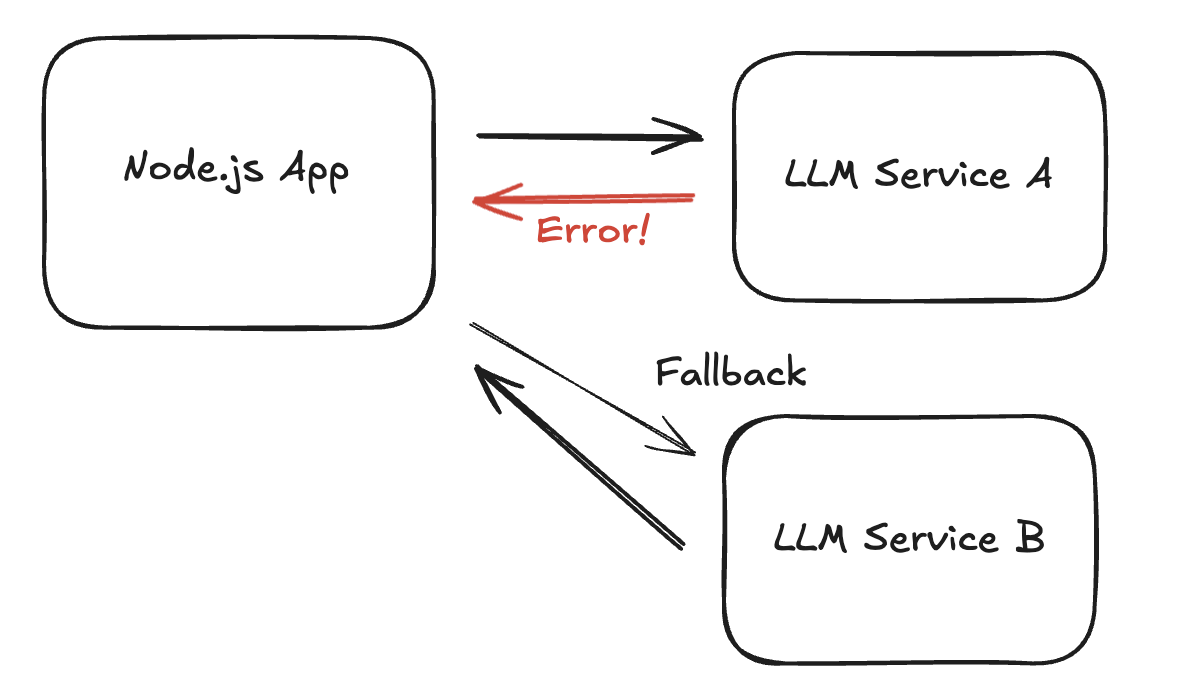
外部の LLM サービスは通常の REST API と比べてレートリミット(一定時間あたりのリクエスト数制限)の制限が厳しいという課題があります。例えば、短時間に大量のリクエストが集中すると、429(Too Many Requests)エラーが返されてサービスが利用できなくなることがあります。
このような特性から、以下のような機能の実装が求められていました。
求められていた機能
1. システムビジー判定機能
外部 LLM サービスでエラーが頻出した場合、システムが過負荷状態にあることをユーザーに周知する機能です。これにより、ユーザーは「システムが調子悪いのかな?」と把握でき、不必要にリトライを繰り返すことを防げます。
2. フォールバック機能
メインで利用している LLM サービスがレートリミット超過でエラーを返した場合、自動的に別の LLM サービスへ切り替える機能です。例えば、Gemini がレートリミットに達したら、自動的に Bedrock へフォールバックすることで、サービスの可用性を高めます。
課題: どうやって動作検証するか?
フォールバック機能やシステムビジー判定機能を実装したものの、大きな問題が残っていました。それは、「どうやってテストするか?」ということです。
これらの機能は「エラーが発生した時」に動作するものですが、外部の LLM サービスを意図的に失敗させることは現実的ではありません。本番環境でレートリミットに達するまでリクエストを送り続けるわけにもいきませんし、開発環境でも同様の制限があります。
そこで、どうやってエラーをシミュレートして動作検証を行うか、いくつかの方式を検討しました。
方式案 1: 製品コードに手を入れる
最もシンプルな方法は、LLM サービスを呼び出している箇所に、テスト用のコードを追加することです。
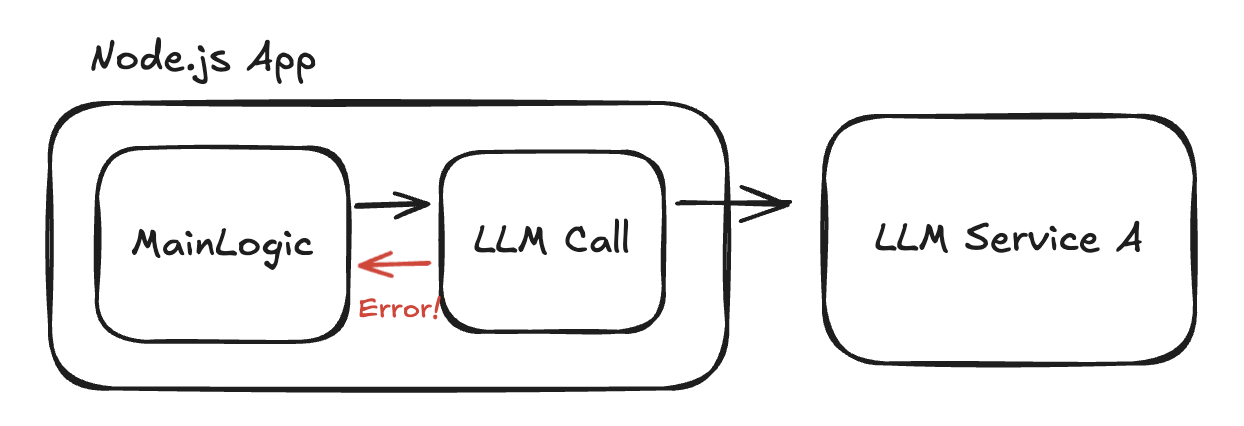
// 例: LLM サービスの呼び出し部分 async function callLLM(prompt) { // テスト用: ランダムにエラーを返す if (Math.random() < 0.5) { throw new Error('Rate limit exceeded'); } return await llmService.generate(prompt); }
なお、llmService.generate() は、OpenAI などの LLM サービスのライブラリをイメージしていただければ大丈夫です。
一見手軽に見えますが、以下のような問題点があります:
問題1: 実装が面倒
複数の LLM サービス呼び出し箇所に、同様のテストコードを追加する必要があります。また、エラー率の調整や特定のエラーパターンをシミュレートするために、複雑な条件分岐を書く必要が出てきます。
問題2: 本当に正しくテストできているのか?
今回テストしたいのは、「LLM サービスの API からの HTTP レスポンスをどうハンドリングするか?」という点です。これには、アプリケーションの実装だけではなく利用しているライブラリがどのように HTTP レスポンスをハンドリングするかという挙動も含まれます。
例えば、OpenAI などの LLM サービスを利用するライブラリは、 LLM サービスの API の HTTP レスポンスのステータスコードを見て自動的にリトライを行うなどの機能を持っています。これらの挙動をライブラリの実装レベルで E2E でテストするには、アプリケーション側で上記のようなテストコードでは不十分で、 HTTP レスポンスに介入してエラーを発生させるのが理想的です。
ちなみに外部 HTTP API 呼び出しを行うライブラリは、HTTP リクエストを送るために fetch API を利用していることが多く、OpenAI などの LLM サービスを利用するライブラリも同様に fetch API を利用しています。
しかし、fetch API を外部から注入できるライブラリもあれば、そうでないライブラリもあります。また、依存を注入するには製品コードの変更が必要になります。
問題3: テスト用コードが本番に混入するリスク
コミット前に削除し忘れたり、マージ時に意図せず本番環境にデプロイされてしまう危険性があります。特に、条件分岐で制御している場合、環境変数の設定ミスなどで本番環境でエラーが発生してしまう可能性もゼロではありません。
方式案 2: Proxy を入れる
次に考えたのは、LLM サービスへの通信を仲介する Proxy サーバーを立てて、そこでエラーを inject する方法です。
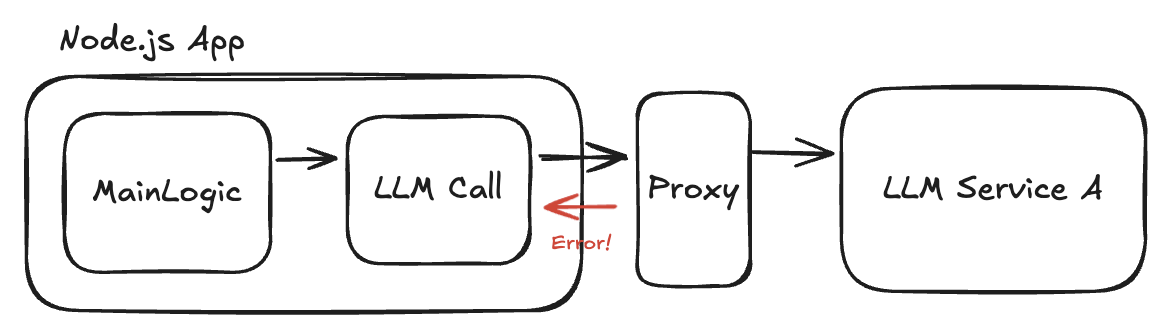
この方法であれば、製品コードを変更せずに済み、実際の HTTP 通信レイヤーでエラーを発生させられます。
しかし、以下のような問題があります:
問題1: インフラ構成に変更が必要で面倒
Proxy サーバーを新たに構築・運用する必要があります。また、ネットワーク設定の変更(アプリケーションから Proxy 経由で通信するように変更)も必要です。
常にこのような機能のテストをする必要があるのであれば、このようなミドルウェアを入れるのも必要になるかもしれませんが、一つの機能のテストのために用意するには少し大げさかもしれません。
問題2: 適切な Proxy ツールの選定が困難
Service mesh(Istio、Linkerd など)の文脈では、このようなエラー注入を行えるツールが存在しますが、私たちのようなシンプルな Node.js アプリケーションで手軽に使えるものは見つかりませんでした。
解決策: fetch API のオーバーライド
2つの方式案を検討した結果、どちらも一長一短がありました。そこで思いついたのが、Node.js のアプリケーション層で fetch API をオーバーライドするという方法です。

この方法では、グローバルに定義されている fetch 関数を独自の実装で置き換え、特定の条件を満たすリクエストに対してエラーレスポンスを返すようにします。
実装の仕組み
以下が、実装の概念を示すコードです:
(() => { // 1. オリジナルの fetch 関数を保存 const origFetch = globalThis.fetch; // 2. fetch 関数を独自実装で上書き globalThis.fetch = async function patchedFetch(input, init = {}) { // 3. エラー注入の対象かどうかを判定 if (isInjectTarget(input)) { // 4. エラーレスポンスを生成して返す const res = new Response("rate limited (simulated)", { status: 429, // Too Many Requests }); return res; } // 5. 対象外の場合は、オリジナルの fetch を呼び出す return origFetch(input, init); }; })();
それぞれの部分を詳しく見ていきましょう。
1. オリジナルの fetch 関数を保存
const origFetch = globalThis.fetch;
まず、Node.js のグローバルオブジェクト(globalThis)に定義されている元の fetch 関数への参照を保存しておきます。これは、エラーを注入しない通常のリクエストでは、本物の fetch を使って実際に通信を行うためです。
2. fetch 関数を独自実装で上書き
globalThis.fetch = async function patchedFetch(input, init = {}) {
次に、globalThis.fetch を独自の関数で上書きします。これにより、アプリケーション内のどこで fetch() が呼び出されても、この独自実装が実行されるようになります。製品コードには一切手を加えずに、すべての fetch 呼び出しをフックできるのがポイントです。
3. エラー注入の対象かどうかを判定
if (isInjectTarget(input)) {
input には fetch 関数に渡した URL が入ってきます。 ここでは URL を見て、エラーを注入すべきかどうかを判定しています。実際の実装では、以下のような条件を設定できるようにしています。
- 特定のホスト(例:
generativelanguage.example.com)へのリクエストのみ対象 - 一定の確率(例: 30%)でエラーを返す
- 環境変数で注入の有効/無効を切り替える
4. エラーレスポンスを生成して返す
const res = new Response("rate limited (simulated)", { status: 429, // Too Many Requests }); return res;
Response オブジェクトを使って、HTTP エラーレスポンスを生成します。ステータスコード 429 は「Too Many Requests」を意味し、レートリミット超過を示す標準的なコードです。このように、実際の LLM サービスが返すエラーレスポンスと同じ形式でレスポンスを返すことで、より本番に近い環境でテストができます。
5. 対象外の場合は、オリジナルの fetch を呼び出す
return origFetch(input, init);
エラー注入の対象でない場合は、最初に保存しておいたオリジナルの fetch を呼び出します。これにより、通常の HTTP 通信は問題なく動作します。
実際の実装
実装には、以下のような機能も追加されています:
- 環境変数でエラー注入の確率を調整可能
- 対象ホストの指定(正規表現での指定も可能)
- エラーレスポンスの種類の選択(429 以外にも、500、503 など)
使い方
このモジュールの素晴らしい点は、Node.js の --import オプションを使うだけで有効化できることです。製品コードには一切変更を加える必要がありません。
# 通常の起動 node server.js # エラー注入を有効にした起動 node --import ./ratelimit-injector.mjs server.js
--import オプションを利用することでアプリケーションの起動前に指定したモジュールを読み込みます(プリロード)。これにより、グローバルオブジェクトの書き換えなどの初期化処理を、製品コードから独立して行えます。
環境変数で挙動を制御することもできます:
# エラー注入の確率を 30% に設定 INJECT_ERROR_RATE=0.3 node --import ./ratelimit-injector.mjs server.js
実装の利点
この実装には、以下のような多くの利点があります:
1. 製品コードの変更なし
--import オプションで import するだけで有効化できるため、製品コードには一切手を加える必要がありません。テストが終わったら、オプションを外すだけで元に戻せます。git のコミット履歴も汚れません。
2. インフラ変更不要
アプリケーション層だけで動作するため、Proxy サーバーを立てたり、ネットワーク設定を変更したりする必要がありません。開発者のローカル環境でも、ステージング環境でも、同じように簡単に使えます。
3. 本番に近い環境でテスト可能
実際の HTTP 通信レイヤーでエラーレスポンスを返すため、本番に近い環境でテストができます。
4. 柔軟な設定が可能
環境変数でエラー率やターゲットホストを調整できるため、様々なシナリオのテストが可能です。例えば、「10% の確率でエラー」「50% の確率でエラー」など、負荷状況に応じたテストができます。
5. 導入が楽!
何よりも、実装も使い方もシンプルで、めちゃくちゃ楽です。「ちょっとエラーケースのテストをしたい」という時に、すぐに試せるのが最大のメリットです。
検証結果
この仕組みを使って、フォールバック機能とシステムビジー判定機能の動作検証を行いました。
→ 無事、両方の機能が正しく動作することを確認できました!
- Gemini へのリクエストで 429 エラーが返されると、自動的に Bedrock へフォールバックする
- 一定期間内にエラーが多発すると、システムビジー状態として UI に警告が表示される
実際の LLM サービスでレートリミットに達する前に、これらの機能が正しく実装されていることを確認できたのは大きな安心材料となりました。
着想: Datadog の自動計装から
この import を使って fetch API をオーバーライドするアイデアは、普段使っている監視ツール Datadog からヒントを得ました。
Datadog の Node.js 自動計装の仕組み
私たちのアプリケーションでは、Datadog APM(Application Performance Monitoring)を使ってパフォーマンスを監視しています。Datadog の優れた点の一つは、自動計装(Auto Instrumentation)機能です。
自動計装とは、製品コードを変更せずに、HTTP リクエストやデータベースクエリなどを自動的にトレースし、Datadog のダッシュボードに送信してくれる機能です。
この自動計装について、どのように実現されているのか気になって調べてみたところ、 HTTP リクエストなどのトレースは fetch API をオーバーライドして実現していることがわかりました。
つまり、Datadog の SDK は以下のような処理を行っていたのです:
- オリジナルの
fetchを保存 fetchを独自実装で上書き- リクエストの開始時刻を記録
- オリジナルの
fetchを呼び出し - レスポンスが返ってきたら終了時刻を記録し、トレース情報を Datadog に送信
こうして、fetch API をオーバーライドしてエラー注入を行うというアイデアが生まれました。既存の技術を別の用途に応用する良い例だと思います。
Datadog の Node.js ライブラリで自動計装しているコードは以下のリポジトリにあります。
実装時間
アイデアが固まってから実装はスムーズに進みました。
AI(Cursor)を使って、1 時間ほどで作成できました。
具体的には、以下のような流れで実装しました:
- 設計:「fetch をオーバーライドして、特定のホストへのリクエストに対してランダムにエラーを返す」という要件を AI に伝える
- 初期実装:AI が生成したコードをレビューし、細かい調整を指示
- 動作確認:実際にアプリケーションで動かしてみて、期待通りに動作するか確認
- 機能追加:環境変数での制御機能などを追加
AI があることで、「こういう機能がほしい」というアイデアから実装までのスピードが飛躍的に向上しました。特に、今回のような「仕組みは理解しているが、細かい実装は AI に任せたい」というケースでは、非常に有効でした。
AI があって本当によかったです 🤖
カオスエンジニアリングとは
今回の取り組みは、カオスエンジニアリング(Chaos Engineering) と呼ばれる手法の一つです。
カオスエンジニアリングの定義
カオスエンジニアリングとは、意図的にシステムに障害を注入して、エラーが発生しても問題なく動作することを確認する活動のことです。
この手法は、Netflix が 2011年に開発した「Chaos Monkey」というツールが起源となっています。Chaos Monkey は、稼働しているサーバーをランダムにシャットダウンすることで、システムの耐障害性を検証するツールでした。
なぜカオスエンジニアリングが必要なのか?
現代のシステムは、多くのマイクロサービスや外部サービスで構成されており、非常に複雑です。そのため、以下のような課題があります:
1. 障害は必ず発生する
どんなに堅牢なシステムを構築しても、ネットワーク障害、サーバーのハードウェア故障、外部サービスの障害など、様々な要因で障害は発生します。問題は「障害が起きるかどうか」ではなく、「障害が起きた時にどう対応するか」です。
2. テストでは発見できない問題がある
単体テストや統合テストでは、想定されたシナリオしか検証できません。しかし、実際の本番環境では、複数のコンポーネントが複雑に絡み合った状態で障害が発生します。このような「想定外の障害」を事前に発見することは困難です。
3. 本番環境で初めて発覚する問題
「開発環境では動いていたのに、本番環境でエラーが出る」という経験は、多くのエンジニアが持っているでしょう。特に、負荷が高い状態やネットワークが不安定な状態での挙動は、開発環境では再現が難しいものです。
カオスエンジニアリングは、これらの課題に対して、意図的に障害を起こすことで、システムの弱点を事前に発見し、改善するというアプローチです。
カオスエンジニアリングのメリット
今回の実装を通じて、以下のようなメリットを実感しました:
1. 耐障害性の確認ができる
「フォールバック機能が本当に動作するか?」「システムビジー判定が正しく機能するか?」といった疑問を、実際にエラーを発生させることで確認できます。
2. 本番環境でのトラブルを事前に防げる
開発段階でエラーハンドリングの不備を発見できるため、本番環境でユーザーが困ることを未然に防げます。
3. 開発者の自信につながる
「障害が起きても大丈夫」という確信を持って機能をリリースできます。これは、精神的にも大きなメリットです。
今回の実装の位置づけ
今回実装した fetch API のオーバーライドによるエラー注入は、カオスエンジニアリングの中でもアプリケーション層でのフォールトインジェクション(Fault Injection) と呼ばれる手法に分類されます。
従来のカオスエンジニアリングツールは、インフラ層(サーバー、ネットワークなど)での障害注入が中心でしたが、今回のようにアプリケーション層で障害を注入することで、より手軽にカオスエンジニアリングを実践できます。
まとめ
この記事では、Node.js アプリケーション層でのカオスエンジニアリングについて、実際の実装事例をもとに解説しました。
記事の要点
今回の取り組みでは、外部LLMサービスのレートリミット対策として導入したフォールバック機能の動作を検証することが大きな課題となっていました。従来は、こうした障害状態を意図的に再現するのが難しく、現実的なレートリミットの発生時でしか確認できませんでした。そこで、fetch APIをオーバーライドし、特定のホストへのリクエスト時にエラーレスポンスを注入する仕組みを自作しました。Node.jsの--importオプションを活用することで、製品コードには一切手を加えず、開発・テスト用の設定を柔軟に有効化できるようにしています。
この実装によって、インフラの設定や本番コードを変更する必要がなく、本番環境に近い状態でさまざまなエラーケースを再現・検証できるようになりました。構成もシンプルで、AIを活用したことにより、着想からわずか1時間で仕組みを構築することができました。
今回のアイデアは、Datadogの自動計装機能がfetch APIをオーバーライドしている仕組みを観察したことがきっかけです。もともとはインフラ層での障害注入が主流だったカオスエンジニアリングですが、アプリケーション層でのフォールトインジェクションをあえて実装することで、より手軽かつ柔軟に耐障害性の確認ができるようになりました。
医療系アプリケーションでの重要性
カケハシが提供するサービスは、医療現場で利用されるシステムです。医療現場では信頼性が最重要な業務が行われています。
そのため、以下のような要件が求められます:
- 高い可用性:システムが使えないと、業務が止まってしまう
- 適切なエラーハンドリング:エラーが発生しても、ユーザーに分かりやすく伝える必要がある
- 障害時の代替手段:メインの機能が使えなくても、別の手段で業務を継続できるようにする
今回実装したフォールバック機能は、まさにこのような要件に応えるものです。Gemini がレートリミットに達しても、自動的に Bedrock へ切り替わることで、ユーザーは AI アシスタント機能を継続して利用できます。
そして、このような重要な機能が正しく動作することを、カオスエンジニアリングによって事前に確認できたことは、大きな価値があったと思います。
今回紹介した fetch API のオーバーライドという手法は、シンプルでありながら強力で、誰でも簡単に実践できます。ぜひ、皆さんのプロジェクトでも試してみてください。
カケハシでは今後も、信頼性の高いシステム開発に取り組み、医療現場を支えるテクノロジーを提供していきます。