カケハシのプラットフォームチームのテックリードとして組織管理サービスと認証基盤を開発している kosui (![]() id:kosui_me) です。今回は、目的別データベースをプラットフォームチームではどのように実践しているかご紹介します。
id:kosui_me) です。今回は、目的別データベースをプラットフォームチームではどのように実践しているかご紹介します。
この記事は秋の技術特集 2024の 13 記事目です。
背景
医療の分野で様々な SaaS を提供するカケハシでは、患者や医療従事者の個人情報を保護するためのセキュリティや、命をつなぐ医療の現場を支える可用性が重要です。
一方で、プロダクトによって重要となる品質や機能は異なります。例えば、薬歴システムを提供する Musubi では、災害時も薬剤師が患者の健康状態を参照できるように復旧しやすさが重要となります。一方で、顧客の経営指標を可視化する Musubi Insight では大量のデータを迅速に集計結果へ反映する性能・拡張性が重要となります。
そこで、システムへ要求される機能要件・非機能要件に応じたデータベースの使い分けが重要となります。AWS は目的別データベース を掲げ、様々な用途に応じて多様なデータベースサービスを提供しています。
では、具体的にどのようなユースケースでデータベースを使い分ければ良いのでしょうか。
目的
この記事では、実際に目的別データベースを実践するカケハシのプラットフォームチームから運用事例を紹介します。
- 事例1: PostgreSQL の行レベルセキュリティを活用する組織管理サービス
- 事例2: DynamoDB を活用する認証基盤と Outbox パターンの活用
事例1: PostgreSQL の行レベルセキュリティを活用する組織管理サービス
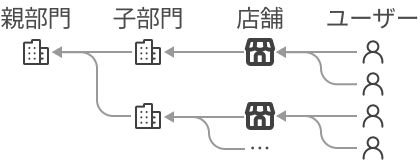
組織管理サービスとは
組織管理サービスは、顧客の法人に属する部署やユーザーを階層的に管理する社内プラットフォームシステムです。各プロダクトでは、統計情報の集計単位や、階層的な権限管理のためにこのサービスを利用しています。
ところで、医療の分野では、個人情報の保護が最重要課題の 1 つとなります。患者の病歴や服薬歴は非常にセンシティブな個人情報であり、個人情報保護法でも「要配慮個人情報」として通常の個人情報とは呼び分けられています。
組織管理サービスは階層的な権限管理に活用されるため、顧客の権限データを他の顧客から参照・変更できないように保護する必要があります。
一方で、SaaS ビジネスでは複数の顧客のデータを取り扱います。ある顧客が他の顧客のデータを参照・変更できないように、データのテナント分離が重要となります。
PostgreSQL の行レベルセキュリティ
そこで、PostgreSQL が提供する機能である、行レベルセキュリティ(Row Level Security)が活躍します。行レベルセキュリティを利用すれば、テーブルの行ごとに参照や変更の権限を柔軟に制御できます。
また、行レベルセキュリティは Aurora PostgreSQL でも利用できます。
ここからは、行レベルセキュリティの機能を例とともに紹介します。例えば、顧客の法人を表現する Organization テーブルと、それぞれの法人に属するユーザーを表現する User テーブルがあるとします。行レベルセキュリティを利用して、foo 法人に所属するユーザーが他の法人から参照・変更できないように保護します。
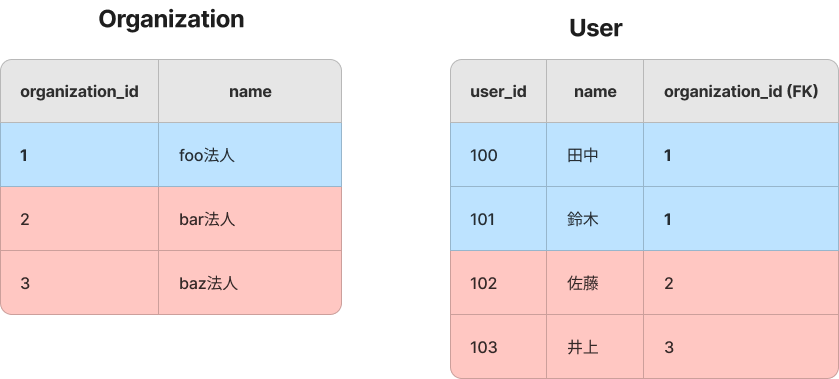
実際に、行レベルセキュリティを user テーブルへ設定してみましょう。
テーブルの行レベルセキュリティを有効化した上で、セキュリティポリシーを定義します。
-- 行レベルセキュリティを有効化 ALTER TABLE user ENABLE ROW LEVEL SECURITY; -- 行レベルセキュリティをテーブルの所有者へ強制 ALTER TABLE user FORCE ROW LEVEL SECURITY; -- セキュリティポリシーを定義 CREATE POLICY user_rls_policy_general ON user USING ( organization_id IN ( SELECT id FROM organization WHERE id = current_setting('app.organization_id', TRUE)::text ) );
それでは、行レベルセキュリティが適切に設定されているか確認しましょう。
以下の例では、user テーブルの全件取得を試みても特定の法人のデータだけが取得されていることが分かります。
-- 何も設定せずに取得を試みると、エラーになる SELECT COUNT(*) FROM `user`; -- unrecognized configuration parameter -- foo法人として取得すると、foo法人に属する2件のみ取得できる SELECT set_config('app.organization_id', 1, true); SELECT COUNT(*) FROM `user`; -- 2 -- bar法人として取得しても同様 SELECT set_config('app.organization_id', 2, true); SELECT COUNT(*) FROM `user`; -- 1
行レベルセキュリティを用いたトランザクションマネージャー
コネクションの作成時に set_config を実行してしまうと、法人ごとにコネクションを作成する必要が生じてしまい、コネクションプーリングが難しくなります。
そこで、トランザクションごとに set_config を実行します。下記の例では、TypeScript とKysely を用いたトランザクションマネージャーの実装を紹介します。
import type { Transaction } from "kysely"; import { Kysely, PostgresDialect, sql } from "kysely"; import type { PoolConfig } from "pg"; import { Pool } from "pg"; // prisma-kyselyなどを利用して生成したテーブル定義の型表現 import type { DB } from "./generated/types"; export class KyselyService { private readonly db: Kysely<DB>; constructor(poolConfig: PoolConfig) { this.db = new Kysely<DB>({ dialect: new PostgresDialect({ pool: new Pool(poolConfig) }), }); } tx<T>( organizationId: string, fn: (transactionClient: Transaction<DB>) => Promise<T> ): Promise<T> { return this.db.transaction().execute(async (t) => { await sql`select set_config('app.organization_id', ${organizationId}, true)`.execute( t ); return fn(t); }); } }
行レベルセキュリティの運用上の注意点
行レベルセキュリティを適用したテーブルへのマイグレーションには注意して下さい。アプリケーション用のロールでマイグレーションを実行してしまうと、データを取得できないままマイグレーションが終了してしまう恐れがあります。よって、アプリケーション用のロールとマイグレーション用のロールは分けておくことをおすすめします。
また、特にパフォーマンスが求められる環境下では、クエリの実行計画が適切であるか事前に確認して下さい。例えば、インデックスが想定通りに適用されているか注意して下さい。
事例2: DynamoDB を活用する認証基盤と Outbox パターンの活用
カケハシの認証基盤刷新
カケハシでは、複数のプロダクトが共通して利用できる認証基盤が存在します。カケハシのビジネスが成長し、エンタープライズ向けシステムとしての側面が強まっています。
それに伴い、医療に関する法令や行政ガイドラインなどのコンプライアンス要件や、多要素認証などのセキュリティ要件への柔軟な対応が必要となりつつあります。
そこで、筆者が所属するチームでは 2024 年春頃より認証基盤の刷新プロジェクトを推進しています。
DynamoDB で実現する高稼働率の認証基盤
カケハシの認証基盤はあらゆるプロダクトで利用されるため、高い稼働率が重要となります。また、大規模障害時や災害時も顧客の業務を継続できる復旧容易性が必要です。
そこで、認証基盤ではセッション情報や認証フローのための一時的な情報を DynamoDB に保存しています。
DynamoDB を採用した理由は次の通りです。
- 高稼働率
パッチ適用やダウンタイムメンテナンスが無い - DynamoDB グローバルテーブル
99.999% の可用性を実現するように設計され、マルチリージョンでマネージドにレプリケーションできる
DynamoDB の特性を考慮する
DynamoDB を採用する場合、DynamoDB の特性を十分に考慮する必要があります。
例えば、DynamoDB は JOIN オペレーションをサポートしていないため、RDB のような正規化されたデータモデリングは適用できません。また、全件取得(スキャン)は金銭面・性能面で高コストであることにも注意が必要です。
加えて、RDB のようにインデックスを自由に追加・削除・変更できることを DynamoDB へ期待してはいけません。DynamoDB ではインデックス(グローバルセカンダリインデックス)を作成する度にテーブルの一部または全てをコピーするため、インデックスの追加は書込の性能を低下させ、金銭的コストも増大します。
しかし、これらの制約を考慮して適切な場面で DynamoDB を採用すれば、DynamoDB は低コストで高可用性を実現したい SaaS プロバイダーにとって強い味方になりえます。DynamoDB はプライマリキー(パーティションキーとソートキー)によってデータの配置先が決定されます。よって、DynamoDB のテーブル設計では、必ず最初にアクセスパターンを明らかにする必要があります。
つまり、キャッシュやセッションなどのアクセスパターンが単純で明快なデータを扱う場合、DynamoDB の活躍が大いに期待できます。認証基盤では、例えば「あるユーザーが他のユーザーの認証情報を参照する」のような要件は今後も発生しえない上に、高い可用性が重要となるため、DynamoDB を採用しました。
- DynamoDB のデータモデリングの基盤 - Amazon DynamoDB
- [GT-2] イラストで学ぶ Amazon DynamoDB ~テーブル設計からパフォーマンスチューニングまで~ | AWS Dev Day 2023 Tokyo #AWSDevDay
CDC と Outbox パターン
また、DynamoDB Streams を活用した変更データキャプチャ(CDC)によってログイン履歴を他プロダクトへ配信することで、ユーザーの行動分析や不正検知などへ利用できます。
カケハシでは、DynamoDB の CDC データを幅広く活用し、あるプロダクトから他プロダクトへリアルタイムなデータ配信を実現しています。
とはいえ、CDC の差分を適切に取り扱うことは想像以上に困難です。差分データを無理に加工してイベントを抽出しようとすると、データ構造の変更時に思わぬ不具合が発生する可能性もあります。
Outbox パターンに従い、アプリケーションのための状態テーブルと、イベント配信のためのドメインイベントテーブルを分けておくことをおすすめします。
まとめ
カケハシでは、医療向け SaaS として共通する要件とプロダクトごとに異なる要件の両面から、目的別にデータベースを選定しています。お読み頂いた皆様の業務にて、設計や議論のきっかけになれば幸いです。