こちらの記事は カケハシ Part1 Advent Calendar 2023 の5日目の記事になります。
こんにちは、カケハシで Musubi Insight のバックエンドエンジニアをしている末松です。
Musubi Insight ではデータ集計バッチに AWS の GlueSparkJob を採用しているのですが、この GlueSparkJob のログレベルを設定することで CloudWatch へのログ収集(DataProcessing-Bytes)にかかっていたコストを98%も削減することができました!!
GlueSparkJob を使われているエンジニアの方にぜひ知っておいていただきたく、紹介させてください!

(画像は私が大好きなイラストやのコストカット侍)
前提
Musubi Insight のチームで GlueSparkJob のログレベル設定が確認できている環境は以下になります。
Type: Spark Glue Version: Glue 4.0 Language: Python 3
ロギング設定ファイルに log4j2.properties を使用している関係で、Glue 2.0 や 3.0 の GlueJob ではログレベルの設定を適用できず(※)、Glue 4.0 にバージョンアップすることで適用できます。(Glue 2.0 や 3.0 に設定しても動作に影響はありません)
※ Log4j 2.x は Spark 3.3.0 以降で利用できるようになるため(Glue 4.0 では Spark 3.3 が動作する)
また今回 CloudWatch へのログ収集(DataProcessing-Bytes)にかかっていたコストの98%を削減できたのは、私たちの CloudWatch 環境において GlueSparkJob のログ収集(PutLogEvents)が支配的だったことが大きく関わります。お使いの環境の利用状況によって効果に違いがありますのでご了承ください。
GlueSparkJob のログについて
GlueSparkJob ではドライバーとエクゼキューター含めて複数台のワーカーが立ち上がり、そのワーカーがそれぞれの CloudWatch ログストリームにログを書き込む仕様になっています。
そしてそのログストリームの中を見ると、非常に詳細なログが出力されていることがわかります。
Musubi Insight チームでは 3 ~ 30台のワーカーを持つ GlueSparkJob を50個近く日々稼働させているため、塵も積もればと言うように気付けば GlueSparkJob の CloudWatch ログにかかるコストが AWS アカウント内のコストの10%近くを占めるようになってしまっていました。
GlueSparkJob のログレベルの設定方法
AWS Glue ジョブによって生成されるログの量を減らすにはどうすればよいですか? -- AWS re:Post を参考に設定していきます。
GlueSparkJob の連続ロギング設定をONにする
Musubi Insight チームでは GlueSparkJob を Terraform で管理しているため、
default_argumentsに以下を追加。"--enable-continuous-cloudwatch-log" = "true" "--enable-continuous-log-filter" = "true"Terraform 以外での設定方法: AWS Glue ジョブの連続ログ記録の有効化 -- AWS Documentation
ロギング設定ファイルを作成
GlueSparkJob にロギング設定を適用させるためには、
log4j.properties設定ファイルを作成して読み込ませる必要がありそうでした。Glue 4.0(Spark 3.3)では Log4j 2 に移行している ので、log4j2.propertiesを作成します。log4j2.propertiesは Glue の Docker イメージ (amazon/aws-glue-libs:glue_libs_4.0.0_image_01) から立ち上げた Docker コンテナー内の/home/glue_user/spark/confにあるlog4j2.propertiesをベースに作成。(ブログの最後に参考情報としてファイルの中身を添付しています)ログレベルを warn から error に変更し、
- rootLogger.level = warn + rootLogger.level = errorS3にアップロードしたら準備完了です。
GlueSparkJob の設定にロギング設定ファイルパスを追加
最後に、アップロードした
log4j2.propertiesの S3 ファイルパスを GlueSparkJob に追加します。"--extra-files" = "s3://<Bucket Name>/<Path Prefix>/log4j2.properties"Terraform 以外での設定方法: 独自のカスタムスクリプトの提供 -- AWS Documentation
以上で設定が完了です。
Log4jに関する懸念
2021年12月に公表された Log4j2 の脆弱性問題 が一時期話題になりました。
この問題は AWS 側で各サービスにパッチが適用されており、Glue に関しても対応されているため問題ないと言えるのではないでしょうか。
ログレベル設定の結果...
ログレベルを設定した結果、
CloudWatch ログの PutLogEvents も大幅に減少し、
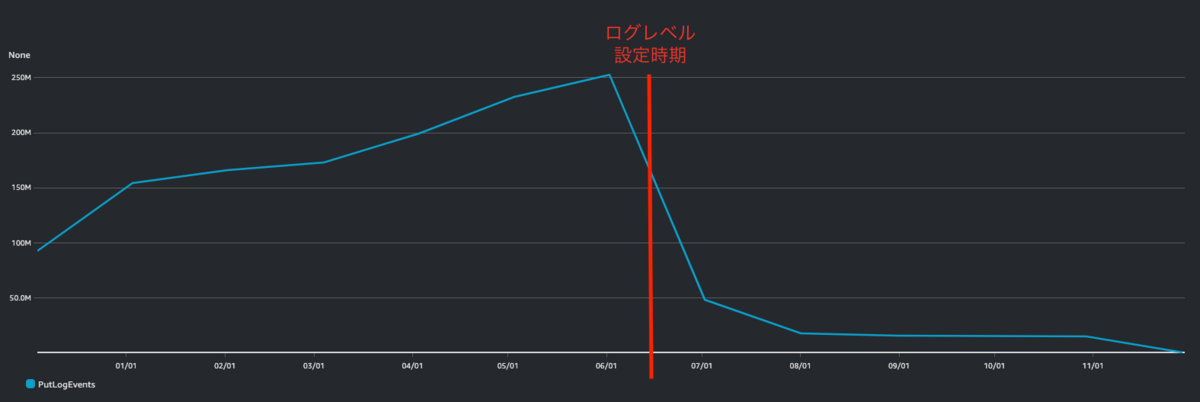
CloudWatch のコストも大幅に減少。
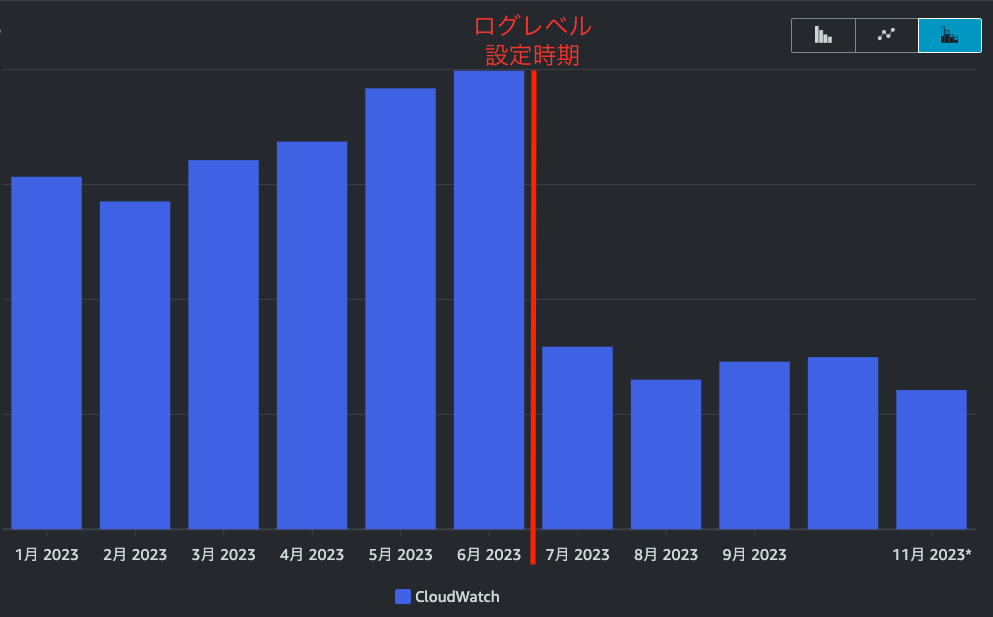
さらにCloudWatch のログ収集(DataProcessing-Bytes)に絞ると、
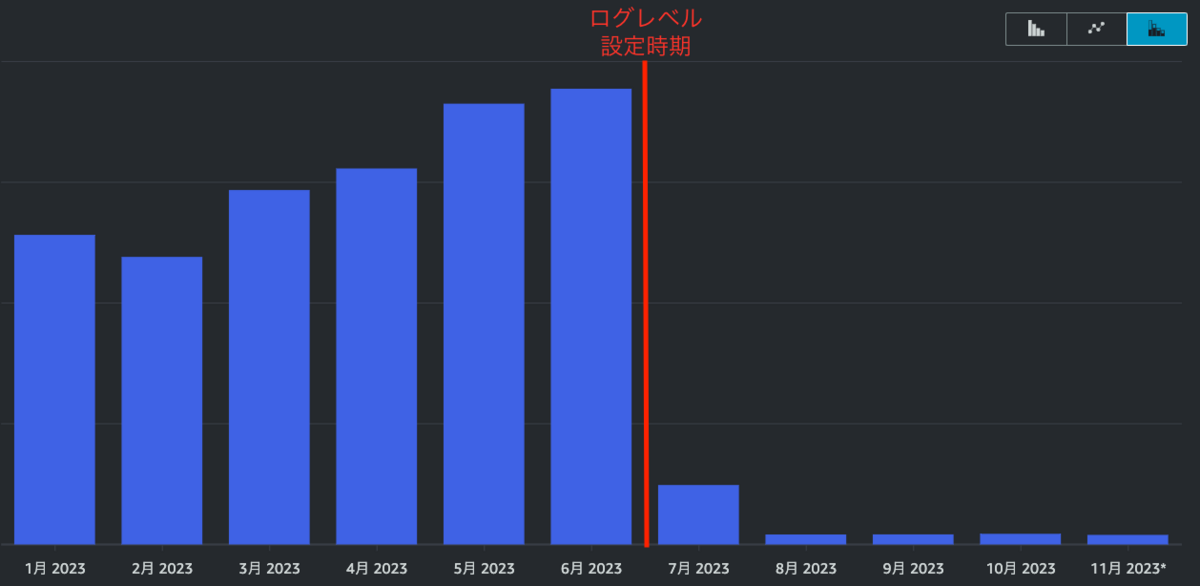
劇的に減少していることがわかります!!
もっとも高かった6月と8月の数値から計算すると、98%もの削減ができたことが判明しました!
最後に
CloudWatch のコストは軽視されがちで、気付いたら結構コストがかかっていたといった状況に陥りやすいと思います。
もし GlueSparkJob を利用している場合、エラーレベルを設定しておくことをオススメします。
そんなMusubi Insight チームでは、データ集計やデータ基盤の設計・構築を得意とするデータエンジニアを募集しています。
ユーザーに直接届くデータを作りたい、整備したい、そんなエンジニアの方はぜひ一度お話ししましょう!
その他にも多種多様なポジションでの採用を行っておりますので、ぜひご確認ください!
参考
Docker コンテナーから入手した log4j2.properties の中身
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# Set everything to be logged to the console
rootLogger.level = warn
rootLogger.appenderRef.stdout.ref = console
# In the pattern layout configuration below, we specify an explicit `%ex` conversion
# pattern for logging Throwables. If this was omitted, then (by default) Log4J would
# implicitly add an `%xEx` conversion pattern which logs stacktraces with additional
# class packaging information. That extra information can sometimes add a substantial
# performance overhead, so we disable it in our default logging config.
# For more information, see SPARK-39361.
appender.console.type = Console
appender.console.name = console
appender.console.target = SYSTEM_ERR
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n%ex
# Set the default spark-shell/spark-sql log level to WARN. When running the
# spark-shell/spark-sql, the log level for these classes is used to overwrite
# the root logger's log level, so that the user can have different defaults
# for the shell and regular Spark apps.
logger.repl.name = org.apache.spark.repl.Main
logger.repl.level = warn
logger.thriftserver.name = org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver
logger.thriftserver.level = warn
# Settings to quiet third party logs that are too verbose
logger.jetty1.name = org.sparkproject.jetty
logger.jetty1.level = warn
logger.jetty2.name = org.sparkproject.jetty.util.component.AbstractLifeCycle
logger.jetty2.level = error
logger.replexprTyper.name = org.apache.spark.repl.SparkIMain$exprTyper
logger.replexprTyper.level = info
logger.replSparkILoopInterpreter.name = org.apache.spark.repl.SparkILoop$SparkILoopInterpreter
logger.replSparkILoopInterpreter.level = info
logger.parquet1.name = org.apache.parquet
logger.parquet1.level = error
logger.parquet2.name = parquet
logger.parquet2.level = error
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
logger.RetryingHMSHandler.name = org.apache.hadoop.hive.metastore.RetryingHMSHandler
logger.RetryingHMSHandler.level = fatal
logger.FunctionRegistry.name = org.apache.hadoop.hive.ql.exec.FunctionRegistry
logger.FunctionRegistry.level = error
# For deploying Spark ThriftServer
# SPARK-34128: Suppress undesirable TTransportException warnings involved in THRIFT-4805
appender.console.filter.1.type = RegexFilter
appender.console.filter.1.regex = .*Thrift error occurred during processing of message.*
appender.console.filter.1.onMatch = deny
appender.console.filter.1.onMismatch = neutral
# HADOOP-14596: Suppress "S3AbortableInputStream" WARN messages.
logger.S3AbortableInputStream.name = com.amazonaws.services.s3.internal.S3AbortableInputStream
logger.S3AbortableInputStream.level = error