こちらの記事は カケハシ Advent Calendar 2022 の11日目の記事になります。
今年10月からAI在庫管理の機械学習エンジニアをやっております中野です。
今回は新型ウイルス感染者数予測を例に取ってProphetの性質について見ていきます。 そもそも新型ウイルス感染者数予測のようなタスクに時系列予測モデルで立ち向かうのは無理ゲーなのですが、我々エンジニアには何とか予測値を捻り出さないといけない状況もままあるでしょう。 環境の変化が激しい系列ではProphetはどの程度使い物になるのでしょうか。
この記事で扱う内容
- Prophetの数理的な性質
この記事で扱わない内容
- 感染者数予測の数理モデリング
- 新規感染者数そのものを目的変数とすることを想定しています。
- COVID-19に関する政策評価
以下ではタイトルにある2つの理由を議論して、最後により好ましいと考えられるアプローチについて紹介します。
1. 中長期のトレンド変化を表現できない
他の時系列モデルでも中長期トレンドの推定は困難なのですが特にProphetではつまらない予測結果になりがちです。
2020年と少し古いですがProphetで感染者数予測をしている記事(以下[2020])がありましたのでこれを基にします。
[2020]は単純な感染者数予測が目的ではなくて、介入前データで学習したモデルの予測値と実績値の比較で政策評価しようという意欲的な試みです。 ここでベースの時系列モデルとしてProphetを採用しているため分析結果が評価し辛いものになっています。
「予測モデルの精度を検証する」の節で、バックテストやテスト期間の予測精度が良好であることを根拠にProphetモデルが感染拡大の様子を一定捕捉できているとしているのですが、これに自信を持つのは難しそうです。 月曜と火曜に数が少ないという傾向は捉えられていますがフィット感を生み出しているのはトレンド項が殆どです。2020年11月からの感染拡大がテスト期間の12月末まで継続したので予測精度が高くなっていますがProphetモデルは将来の収束については何も考えていません。(分析者も「もちろん、環境に大きな変化(トレンド変化など)が生じた場合にはProphetの予測が役に立たなくなることもある点には注意が必要です。」とコメントしています)
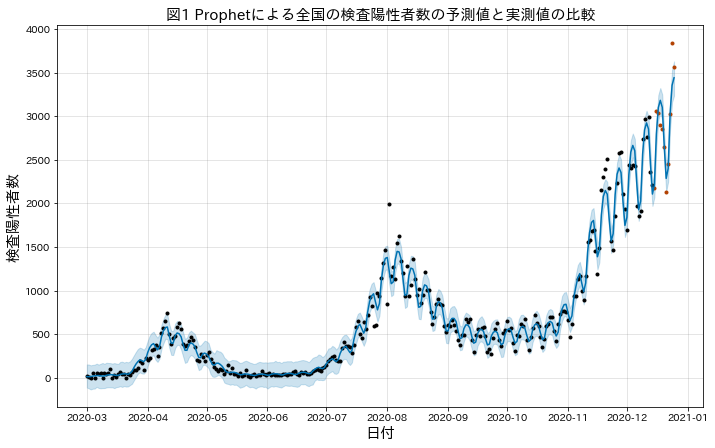
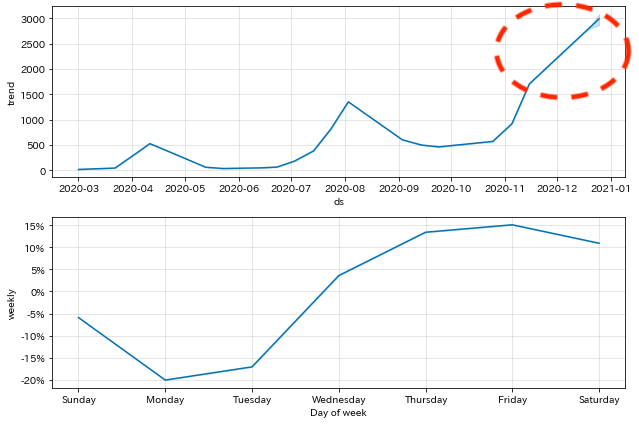
Prophetにはトレンド変化点の検出機能がありますが(当然)過去データから変化点を探すだけです。予測時のトレンドは学習データ最後の推定結果に単にノイズを乗せたものになります。
もっと分かりやすい例が「10月のGoToトラベルへの東京参加・GoToイートの影響を測定する」の節です。 感染の落ち着いていた2020年10月が学習期間の最後だったためテスト期間の予測がフラットになってしまっておりGoTo施策の悪影響が大きめに評価されています。
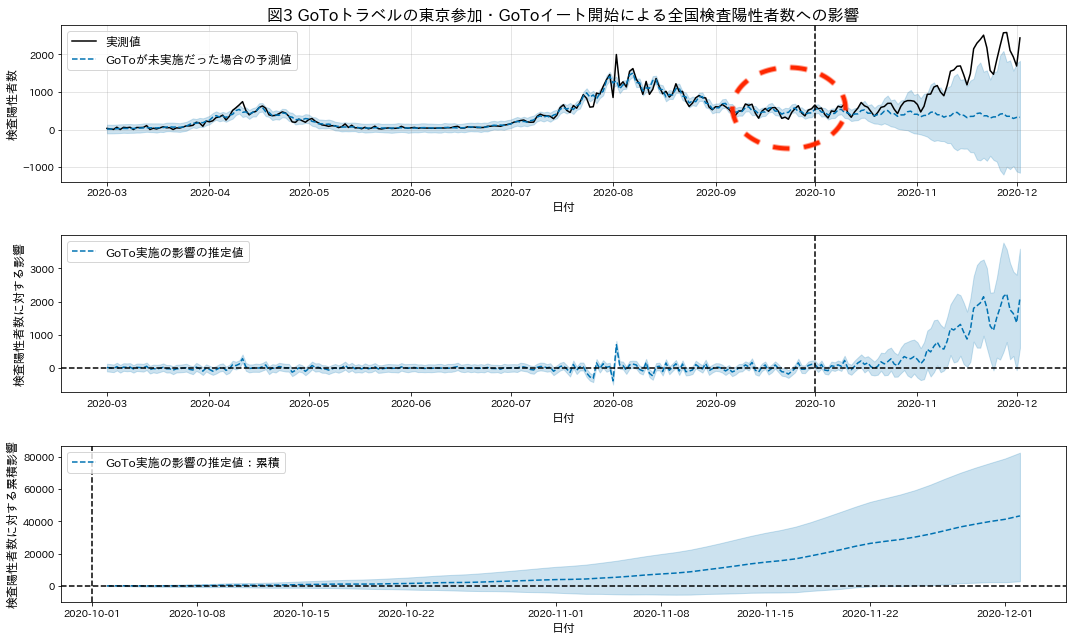
やはりProphetを中長期予測に用いるのは問題が多いと言わざるを得ないでしょう。
補: 因果推論について
2022年時点ではデータが豊富に集まっているため通常の因果推論の手法で政策評価ができるようになっています。
ただし地方のデータを使ってまん延防止等重点措置のなかった反実東京をシミュレートできるのかについては議論もあるようです。 Future Covariateを使った性能の良い時系列モデルが用意できるのであれば[2020]のようなアプローチの方が実務的には納得感があるのではないかとも考えています。
2. 短期予測でもトレンド変化への対応が遅い(ことがある)
短期予測であればトレンド変化の影響を受ける確率が低くなります。しかしこの場合においてもProphetには少量観察されたトレンド変化への反応が悪くなることがあります。
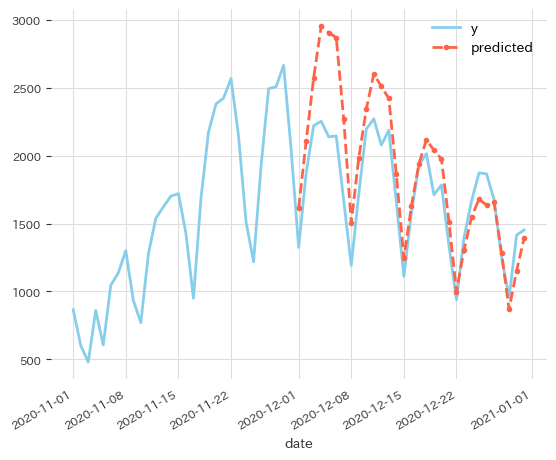
何らかの事情で2020年12月1日から新規感染者が減少するようなデータを作ってみます。トレンドとは無関係なショックなので12月1日分では予測不可能ですが2日以降で予測を修正できるかというのが観点になります。
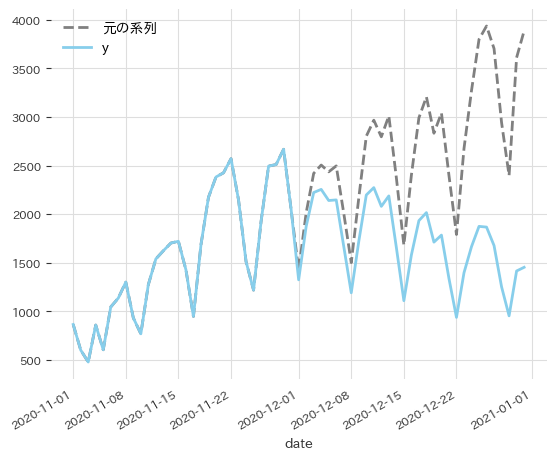
短期予測ということで当日までのデータを使って翌日1日分の予測を繰り返して予測のズレを調べます。
def backtest(ds, model, kwargs, y_col='yhat'): forecast = [] for ii in range(n-p, n): d_train = ds.iloc[0:ii] m = model(**kwargs) m.fit(d_train) future = m.make_future_dataframe(1, freq='D') predict = m.predict(future) forecast.append(predict.iloc[-1][y_col]) return forecast prm = { 'seasonality_mode': SEASONALITY_MODE, 'seasonality_prior_scale': SEASONALITY_PRIOR_SCALE, 'changepoint_range': 1.0, 'changepoint_prior_scale': CHANGEPOINT_PRIOR_SCALE, 'n_changepoints': 15, } backtest(ds, Prophet, prm)
このケースではトレンド変化を織り込むのに概ね2週間かかってしまいました。
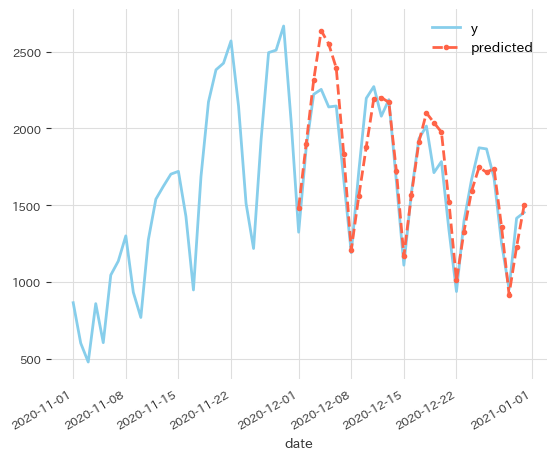
先の実験では n_changepoints をデフォルトより少なくしていました。変化点の上限を増やしましょう。
prm = {
'seasonality_mode': SEASONALITY_MODE,
'seasonality_prior_scale': SEASONALITY_PRIOR_SCALE,
'changepoint_range': 1.0,
'changepoint_prior_scale': CHANGEPOINT_PRIOR_SCALE,
'n_changepoints': 30,
}
backtest(ds, Prophet, prm)
こうすると1週間で織り込まれるようになりました。1週間でトレンドに追従できるなら十分でしょう。
パラメータを変えて実験してみたところ
n_changepointsが極端に少ないと学習時の精度が悪くなる。n_changepointsがモデル初回構築時に適切な数だとモデル更新時にトレンド変化の捕捉が遅れる。n_changepointsが多いと学習が重くなる。
という傾向がありました。特に学習データが長期間になるときは n_changepoints を多めに取っておくのが良さそうです。
短期予測の改善
Prophetよりも短期予測に強いと期待されるライブラリにNeuralProphetがあります。
論文でも "Prophet lacks local context, which is essential for forecasting the near-term future" と書かれています。
外部変数を使わないときのモデル式は以下のようになります。Prophetでも使われているトレンド と周期性
に自己回帰の項
が加わっています。
自己回帰の項があるため過去のトレンドから外れたショックがあったときに次の予測値でそれを取り込みやすくなります。
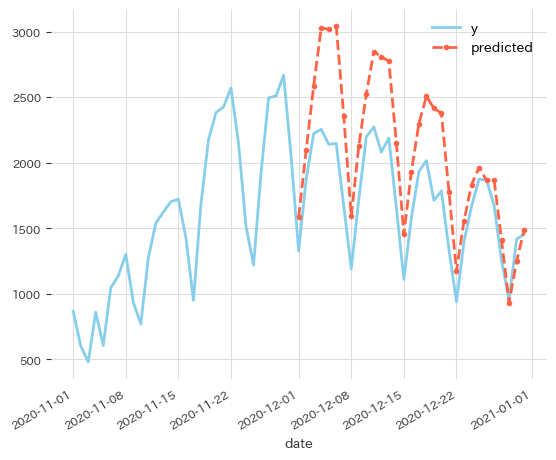
Prophetと同様の実験をしてみましょう。
def backtest(ds, model, kwargs, y_col='yhat'): forecast = [] for ii in range(n-p, n): d_train = ds.iloc[0:ii] m = model(**kwargs) m.fit(d_train, freq='D') future = m.make_future_dataframe(d_train, periods=1, n_historic_predictions=True) predict = m.predict(future) forecast.append(predict.iloc[-1][y_col]) return forecast prm = { 'seasonality_mode': SEASONALITY_MODE, 'changepoints_range': 1.0, } backtest(ds, NeuralProphet, prm, 'yhat1')
トレンド変化に追いつくのに3週間かかってしまいました。Prophetより悪化しています。
n_changepoints を大きくしてみます。
prm = {
'seasonality_mode': SEASONALITY_MODE,
'changepoints_range': 1.0,
'n_changepoints': 30,
}
backtest(ds, NeuralProphet, prm, 'yhat1')
先ほどより反応は良くなりました。オリジナルのProphetと比べて12月2日と3日の予測値がやや良さそうですが全体的には似たような挙動に見えます。
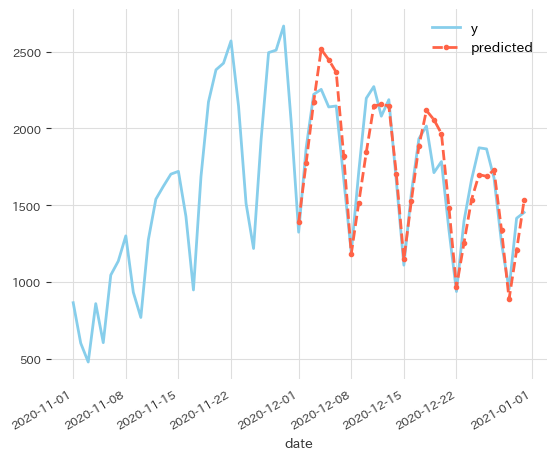
トレンド項によってもフィットできるため自己回帰の係数がそれほど大きくないものと考えられます。 また、曜日効果が強烈な系列なので日単位のラグで回帰がうまくいっていない可能性もあります。季節調整後の自己回帰をすることで精度改善できないかは冬休みの宿題にしたいと思います。
芳しい結果は得られませんでしたが計算時間についても確認しておきましょう。 NeuralProphetは自己回帰の項のためにProphetと異なりPyTorchで最適化をしています。
%%timeit -n 1 -r 1 model = Prophet( seasonality_mode=SEASONALITY_MODE, seasonality_prior_scale=SEASONALITY_PRIOR_SCALE, changepoint_range=CHANGEPOINT_RANGE, changepoint_prior_scale=CHANGEPOINT_PRIOR_SCALE ) model.fit(ds_train) # 133 ms %%timeit -n 1 -r 1 model = NeuralProphet( seasonality_mode=SEASONALITY_MODE, changepoints_range=CHANGEPOINT_RANGE, ) model.fit(ds_train) # 3.39 s
通常のProphetと比べて1桁以上遅くなっていますが現実的な計算時間で安定した推定結果が得られている感触です。 トレンドと周期性はProphetと同じ形に制限されているため他のDeep時系列モデルと比べて大幅にパラメータを減らせているものと考えられます。
まとめ
新型ウイルス感染者数予測のような変化の激しいデータについてProhpetやNeuralProphetの挙動を確認しました。 この設定であればNeuralProphetが勝ると考えていたのですがProphetの安定感を見せつけられる結果となりました。 このようなデータにProphetが適していない理由は確かに存在するのですが、限界を理解した上で使うのであれば手軽に一定の精度を得られそうです。
カケハシの機械学習エンジニアは以上のようなことも考えながらAI在庫管理の精度改善に日々取り組んでおります。ご興味のある方は是非是非お問合せください。
参考
- [2020] GoToトラベルと感染拡大の因果関係は?GoTo停止は感染に歯止めをかけるか? (2020-12)
- 気象変化と新型コロナ感染/予測の可能性と新事実 (2021-02)
- まん延防止等重点措置の政策評価レポート (2022-03)
- COVID-19 AI・シミュレーションプロジェクト LSTMで感染者数を予測するチームがありました。
- [R] fb Prophet の解剖で学ぶベイズ時系列モデリング
- Prophetを、リクルートグループWebサイトの数カ月先の日次サーバコール数予測で活用してみた話
- あまりに暑いので、ごく簡単に Prophet の分析の質を向上させる方法を書いた Prophetと自己相関についてコメントされています。
- Is Facebook's "Prophet" the Time-Series Messiah, or Just a Very Naughty Boy? Prophetの挙動を細かい所まで調べていて興味深いです。
- Prophet vs DeepAR: Forecasting Food Demand