Musubi AI在庫管理の機械学習エンジニアをやっている中野です。
こちらの記事は カケハシ Advent Calendar 2023 の1日目の記事になります。 昨年はprophetについて書きましたが今年は勾配ブースティングにしました。
医薬品や食料品、アパレルなどの需要予測において平均値ではなく95%点や99%点を要求されるケースがままあります。 例えばコンビニおにぎりの在庫管理において需要予測の平均値だけ発注していれば2回に1回程度は欠品してしまうでしょう。こういった場合に予測の95%点を発注すれば欠品をおよそ20回に1回へと低減できます。
GBDTでもこのような確率点を返す予測が可能なのですが解釈や使い方には注意が必要そうです。
分位点回帰とは
MAEを最小化するモデルが中央値を予測しているのはよく知られていますが分位点回帰はこれを一般化したものです。
分位点回帰では以下のようなロス関数を最小化します。 $$ L_{\alpha}(y, \hat{y}) = \begin{cases} (1 - \alpha) (\hat{y} - y) \quad & y - \hat{y} < 0 \\ \alpha (y - \hat{y}) \quad & y - \hat{y} \geq 0 \end{cases} $$ ここで $y, \hat{y}$ はそれぞれ観測値と予測値です。 例えば $\alpha=0.05$ では $\hat{y} \leq y$ のときの誤差が軽視されるため平均より小さい予測にすることでロスを改善できます。 証明は省略しますが、このロス関数でモデルを構築すると $\alpha$ %確率点が予測値になります。
各種GBDTライブラリでも以下のような設定で実行できます。
- scikit-learn:
GradientBoostingRegressor(loss='quantile', alpha=alpha) - LightGBM:
LGBMRegressor(objective='quantile', alpha=alpha) - XGBoost:
XGBoostRegressor(objective='reg:quantileerror', quantile_alpha=alpha)(version 2.0で実装)
GBDTでは、葉の中の分散が最小になるようにデータを分割し、葉の中の $\alpha$ %確率点を重みとするようなイメージです。
分位点回帰を用いれば先のコンビニおにぎりのような不確実性の大きい問題に対処できるような気がしますが、この $\alpha$ %確率点というのは学習データにおけるものであり、推論時のそれを近似しているかは学習・テストデータの分布ズレやモデル性能などによって変わってきます。
GBDTによる分位点回帰の解釈には注意が必要だというのが本記事の主旨です。
数値例
例えば80%予測区間を得るためには alpha=0.1 と alpha=0.9 で予測すれば良さそうですが、推論時の予測が予測区間に入る確率が80%から乖離することがあります。
実際に確認してみましょう。 以下のように分散不均一のデータを生成します。
def f(x): return np.log(1 + x['x1']) * np.sin(x['x1']) def sigma(x): w = np.cos(x['x1'] * 0.9) # 周期を少しズラす return np.where(w > 0, w, np.abs(w) / 2) def g(x, upper=True): if upper: q = -1.0 * stats.norm.ppf(0.10) else: q = 1.0 * stats.norm.ppf(0.10) return f(x) + q * sigma(x) rng = np.random.RandomState(0) z = rng.randn(N) zt = rng.randn(N) # 学習データ y = f(x) + z * sigma(x) # テストデータ yt = f(xt) + zt * sigma(xt)
80%予測区間を得るために alpha=0.1 と alpha=0.9 でモデルを学習します。
common_params = {
'n_estimators': 300,
'objective': 'quantile',
}
lst_alpha = [0.1, 0.9]
regs = []
for alpha in lst_alpha:
reg = lgb.LGBMRegressor(alpha=alpha, **common_params)
reg.fit(x, y)
regs.append(reg)
以下で予測区間をプロットしてみます。
common_params = {
'n_estimators': 300,
'objective': 'quantile',
}
lst_alpha = [0.1, 0.9]
regs = []
for alpha in lst_alpha:
reg = lgb.LGBMRegressor(alpha=alpha, **common_params)
reg.fit(x, y)
regs.append(reg)
p_lower = regs[0].predict(xt)
p_upper = regs[1].predict(xt)
fig = plt.figure(figsize=(8, 6))
plt.plot(xt, f(xt), 'g-', linewidth=3, alpha=0.7, label='f(x)')
plt.plot(xt['x1'], yt, 'b.', markersize=2, alpha=0.3, label='test observations')
plt.plot(xt['x1'], g(xt, upper=False), '-', color='purple', linewidth=2, alpha=0.5, label='true upper/lower limit')
plt.plot(xt['x1'], g(xt, upper=True), '-', color='purple', linewidth=2, alpha=0.5)
plt.plot(xt['x1'], p_lower, 'r-', linewidth=1, alpha=0.5)
plt.plot(xt['x1'], p_upper, 'r-', linewidth=1, alpha=0.5)
plt.fill_between(
xt['x1'], p_upper, p_lower, color='pink', alpha=0.8, label='predicted 80% interval'
)
plt.legend(loc='lower left')
plt.show()
紫の線が真の予測区間上下限であり、その周辺をギザギザしている赤の線が推定された予測区間の上下限です。
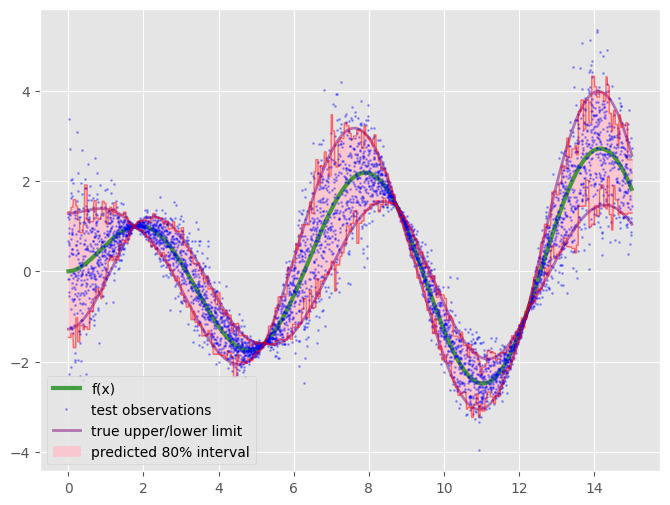
また、テストデータが80%予測区間に入る確率は77%となっていました。
def coverage_fraction(y, y_lower, y_upper): return np.mean(np.logical_and(y >= y_lower, y <= y_upper)) print(coverage_fraction(y, regs[0].predict(x), regs[1].predict(x))) # 0.7974 print(coverage_fraction(yt, p_lower, p_upper)) # 0.7738
分位点回帰でも通常の回帰と同様に推論時の性能は学習時より悪くなります。
推論時の誤差はより大きくなりやすいため、学習時の alpha は推論時に実現したい水準よりもルーズに設定する必要があります。
scikit-learnのドキュメントでもキャリブレーションの一例を紹介しています。
モデルフィット
学習時と推論時での性能差の話になりました。 先のモデルはプロットを見る限り良好な予測ができていそうでしたが、モデルがアンダーフィットしている場合はどのようになるでしょうか。
アンダーフィットさせるため n_estimators を過小にしてみます。
common_params = {
'n_estimators': 30,
'objective': 'quantile',
}
lst_alpha = [0.1, 0.9]
regs = []
for alpha in lst_alpha:
reg = lgb.LGBMRegressor(alpha=alpha, **common_params)
reg.fit(x, y)
regs.append(reg)
先と同様にプロットしてみると予測区間上限が平らになってしまっていることが分かります。
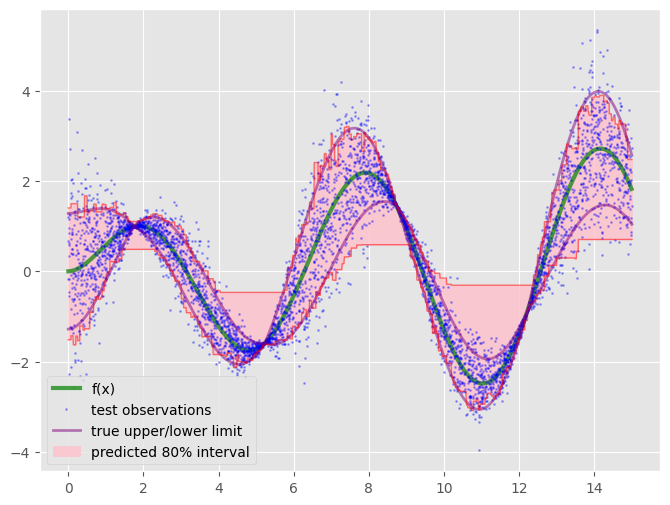
学習データが80%予測区間に入っている確率も86%と乖離があり、学習が不足しているといえます。
print(coverage_fraction(y, regs[0].predict(x), regs[1].predict(x))) # 0.858 print(coverage_fraction(yt, p_lower, p_upper)) # 0.8538
今回は特徴量が1列のデータであるためモデルをオーバーフィットさせにくいのですが、オーバーフィットしている場合は分散推定が過小になるなど予測区間に悪影響が出ます。 通常の分類や回帰と同様に分位点回帰の場合もGBDTの学習は適切なところで停止する必要があります。
正しい使い方
したがって良いモデルの構築と予測区間のキャリブレーションを両立するには以下のような手順を踏む必要があると考えられます。
- バリデーションまたはクロスバリデーションでツリー本数などのハイパーパラメータをチューニングする
- GBDTのパラメータの中で
alphaだけを変化させて再学習しキャリブレーションする
ハイパーパラメータのチューニングと alpha のキャリブレーションをまとめて実行するのは難しいのではないかと思われます。
更にバリデーションでquantile errorの小さいモデルが良いモデルなのかという点にも議論がありそうです。
まとめ
GBDTによる分位点回帰について調べて以下のことが分かりました。
- 分位点回帰は推論時の誤差を評価している訳ではない
- あくまで学習時に予測できなかった誤差の確率点を返している
- GBDTの分位点回帰でより正確な予測範囲を得るためにはキャリブレーションが必要
- 良いモデルのためにはハイパーパラメータのチューニングも必要だがキャリブレーションと両立させるのは容易ではない
このように業務で使うにはいささか不安があります。 次はCatBoost Uncertaintyのようなものが分位点回帰とどのように異なるのか調査してみたいです。