こちらの記事はDatabricks Advent Calendar 2022の25日目の記事になります。
こんにちは、カケハシでMusubi Insightという薬局向けBIツールのバックエンドエンジニアをしている高田と申します。
BIツールを開発しているということもあり日常的にETL処理の実装を行っていますが、普段の開発ではAWS Glueを採用しています。
しかし、カケハシでは全社的なデータ活用基盤のプラットフォームとしてDatabricksが採用されたこともあり、とあるプロジェクトでDatabricksを活用してデータエンジニアやデータアナリストとうまく協業できたので、その時の事例を紹介させていただければと思います。
プロジェクトの背景
Musubi Insightは薬局向けのBIツールであり、薬剤師業務に関する指標や薬局の収益に関する指標など様々な軸でのデータ分析指標を提供しています。
ありがたいことにユーザー数もかなり増えてきており、それに伴いユーザーの抱える課題やニーズも多様化してきています。
そういった課題やニーズに対応するために、よりアドホックな分析が求められているのですが、開発リソースの関係などから対応に時間がかかってしまうなど、顧客への提供価値のボトルネックとなってしまっていました。
そのため、汎用的な要件だけではなくよりニッチな要件にもスピード感を持って対応できるデータ分析基盤を作りたいということで本プロジェクトはスタートしました。
採用したアーキテクチャ
本プロジェクトでは、メダリオンアーキテクチャを採用して、データレイヤーをBronze、Silver、Goldの3つに分離しています。
そして各レイヤーごとに別の役割を持つメンバーが担当しデータ基盤全体の構築を行いました。
アーキテクチャのイメージは以下のようになります。
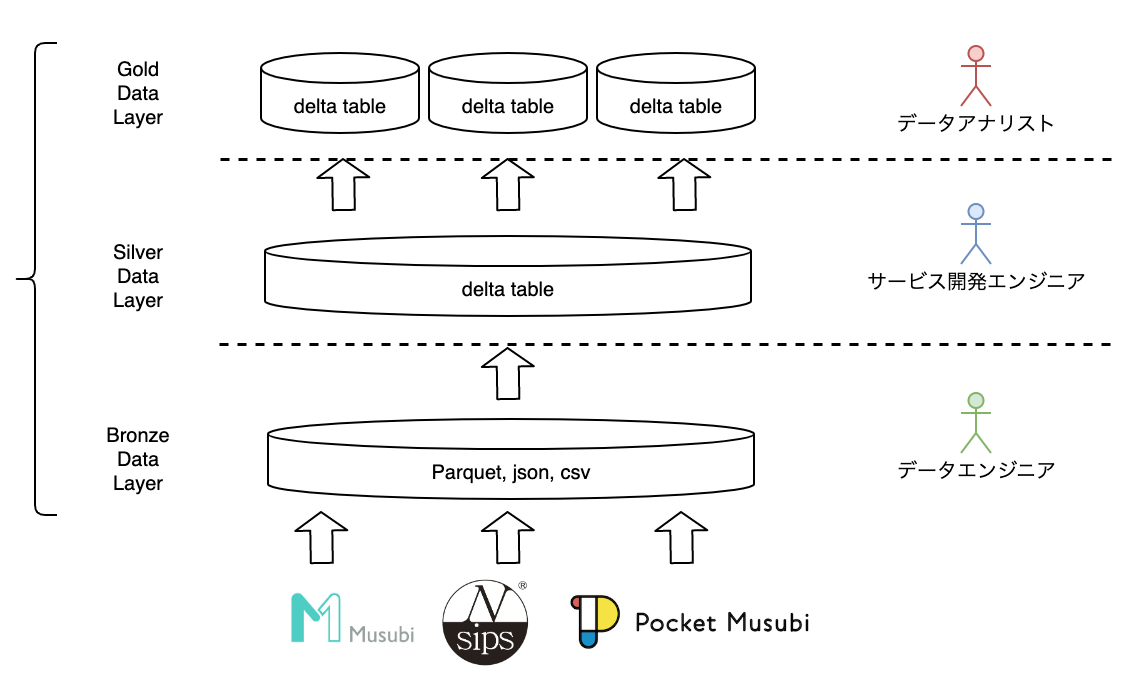
データフォーマットは各レイヤーで様々ですが、実データとしては全てAWSのS3に格納されています。
まず、Bronzeデータレイヤーは全社横断的なデータ基盤チームのデータエンジニアが担当しています。
ここでは、カケハシの他システムからのデータや、薬局のレセプトデータなど多種多様なデータがほとんど生データに近い形で蓄積されています。
そしてSilverデータレイヤーはサービス開発を行なっているエンジニアである私が担当しました。
SilverデータレイヤーではBronzeデータレイヤーで蓄積されたデータの中から、分析に必要なデータの抽出(テーブル、カラム)をはじめとするデータの正規化を行なっています。
また、Silverデータレイヤー以降はエンジニア以外も参照可能なデータであることから、秘匿情報の匿名化など、セキュリティに関する制約もこのレイヤーで加えています。
最後にGoldデータレイヤーはMusubi Insightチームのデータアナリストが担当しています。
Goldデータレイヤーは、実際にユーザーやフロントメンバーとのやりとりを通じてアドホックなデータの作成、分析が行われるデータとなります。
協業を行う上でDatabricksが便利だと感じた点
今回、Databricksを使用してみて、様々な職種のメンバーと協業する上で便利だと感じた点を紹介します。
扱える言語が豊富
まず、扱える言語が豊富という点です。
普段使用しているAWS GlueではPythonかScalaしか扱えません。
データエンジニアであればこれでも問題ないかもしれませんが、データアナリストにとっては少しハードルが高くなってしまうのではないかと思います。
一方DatabricksではPython、Scalaに加えて、RとSQLもNotebook上で扱うことができます。
そのため、SilverデータまではエンジニアがPythonやScalaで構築し、Goldデータはアナリストが使い慣れているRやSQLで構築するといった分業が行いやすくなっていると感じました。
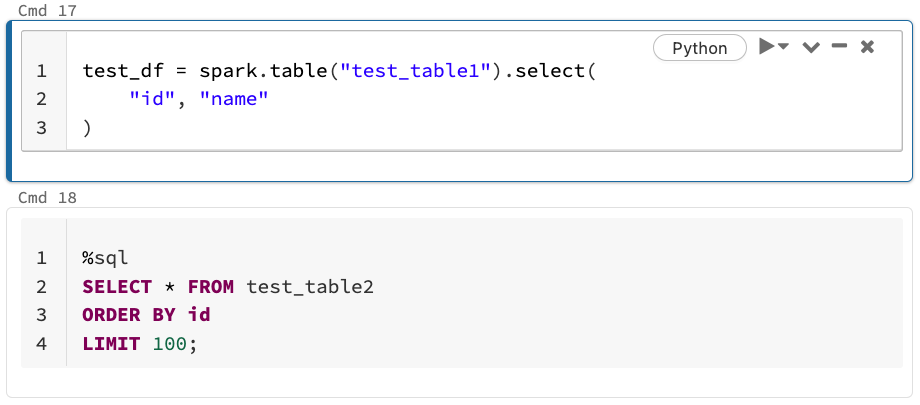
またDatabricksのNotebookの特徴として、1つのNotebook上で異なる言語を併用することができる点が挙げられます。
AWS Glueにおいても最近ではNotebook形式で開発を行うことができますが、Notebook作成時に指定した1つの言語しか扱えません。
しかしDatabricksではデフォルトの言語は指定するものの、以下のようにセルにの先頭に「%言語」というマジックコマンドを記述すると別言語でも使用可能となっています。
そのため基本はPythonで実装して、ある部分だけSQLを使って簡単に書きたい、みたいなこともできます。
柔軟な権限管理
そして権限管理が柔軟な点も分業をやりやすくしている点だと感じました。
カケハシでのDatabricksのデータ権限管理方針については、こちらの記事に詳しく紹介されていますが、ロールにチームや個人を紐付けるロールベースアクセス制御(RBAC)で権限設定されています。
アクセス制御はデータベース、テーブル、SQLビューなど、細かな単位で設定することが可能となっています。
今回の事例ではテーブル単位に制御を行い、次のような設定としました。

基本となる思想としては最小権限の原則に則り、意図していないデータの変更や不必要に秘匿情報の参照が起こらないような設定を行っています。
今後の課題
今回一通りデータ基盤を構築しましたが、まだ作り込みが足りておらず課題として残っている点もあります。
例えば、Bronze、Silver、Goldの各レイヤーでそれぞれPipelineが構築されていますが、現状それらの依存関係をシステム的には定義できていません。
現状では各Pipelineの想定終了時刻から逆算して時刻をトリガーにキックされるのですが、前段のレイヤーの処理が想定以上に伸びてしまった場合、後段のPipelineは前段のデータができていない状態でも起動してしまいます。
こちらはDatabricksによって提供されている開発者向けAPIが使用できそうなので、前段のレイヤーのPipeline終了時に次のレイヤーのPipelineをトリガーするような処理を追加していきたいと考えています。
また、これまでDatabricksのPipelineのエラー通知はメールしか選択できず、送信内容のカスタマイズも出来ないというお世辞にも使いやすいものとは言えませんでした。
しかし、本記事の執筆時点ではパブリックプレビュー版ではありますが、Slack/Teams/Webhook/PagerDutyにも通知ができるようになりました。
カケハシではSlackやPegerDutyを使用しているので、新機能のお試しを兼ねて設定変更を行なっていきたいと思います。
最後に
今回はDatabricksを使用して様々な職種のメンバーで協業してデータ基盤を構築した事例を紹介させていただきました。
Databricksを導入することで、技術的なハードルが下がり、かつ柔軟な権限設定ができることによって、セキュアでかつスピーディーに顧客に価値を提供できるようになりました。
これまではデータ基盤チームの中央集権的な集中管理であったデータを、各ドメインチームがデータ作成・権限作成できるようになったことで、全社的にもよりデータの利活用が活発化するような感じがしています!
本記事が特にまだDatabricksを用いたデータ基盤構築にイメージが湧いていない方の参考となれば幸いです。
そんなDatabricksを導入しているカケハシですが、現在多種多様なポジションで一緒に働ける仲間を募集しております!